


II. Les bases▲
Dans ce chapitre, nous prÃĐsentons les bases de la programmation Web. Il a pour but essentiel de faire dÃĐcouvrir les grands principes de la programmation Web avant de mettre ceux-ci en pratique avec un langage et un environnement particuliers. Il prÃĐsente de nombreux exemples qu'il est conseillÃĐ de tester afin de "s'imprÃĐgner" peu à peu de la philosophie du dÃĐveloppement web.
II-A. Les composantes d'une application Web▲
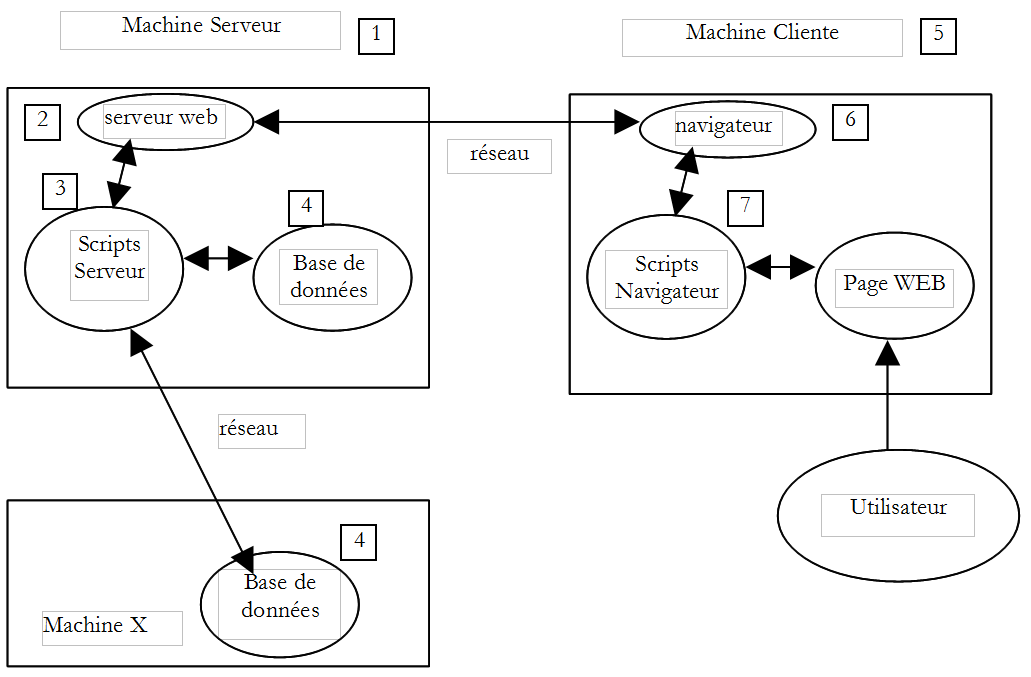
| NumÃĐro | RÃīle | Exemples courants |
| 1 | OS Serveur | Linux, Windows |
| 2 | Serveur Web | Apache (Linux, Windows) IIS (NT), PWS(Win9x) |
3 |
Scripts exÃĐcutÃĐs cÃītÃĐ serveur. Ils peuvent l'Être par des modules du serveur ou par des programmes externes au serveur (CGI). | PERL (Apache, IIS, PWS) VBSCRIPT (IIS,PWS) JAVASCRIPT (IIS,PWS) PHP (Apache, IIS, PWS) JAVA (Apache, IIS, PWS) C#, VB.NET (IIS) |
| 4 | Base de donnÃĐes - Celle-ci peut Être sur la mÊme machine que le programme qui l'exploite ou sur une autre via Internet. | Oracle (Linux, Windows) MySQL (Linux, Windows) Access (Windows) SQL Server (Windows) |
| 5 | OS Client | Linux, Windows |
| 6 | Navigateur Web | Netscape, Internet Explorer |
| 7 | Scripts exÃĐcutÃĐs cÃītÃĐ client au sein du navigateur. Ces scripts n'ont aucun accÃĻs aux disques du poste client. | VBscript (IE) Javascript (IE, Netscape) Perlscript (IE) Applets JAVA |
II-B. Les ÃĐchanges de donnÃĐes dans une application web avec formulaire▲
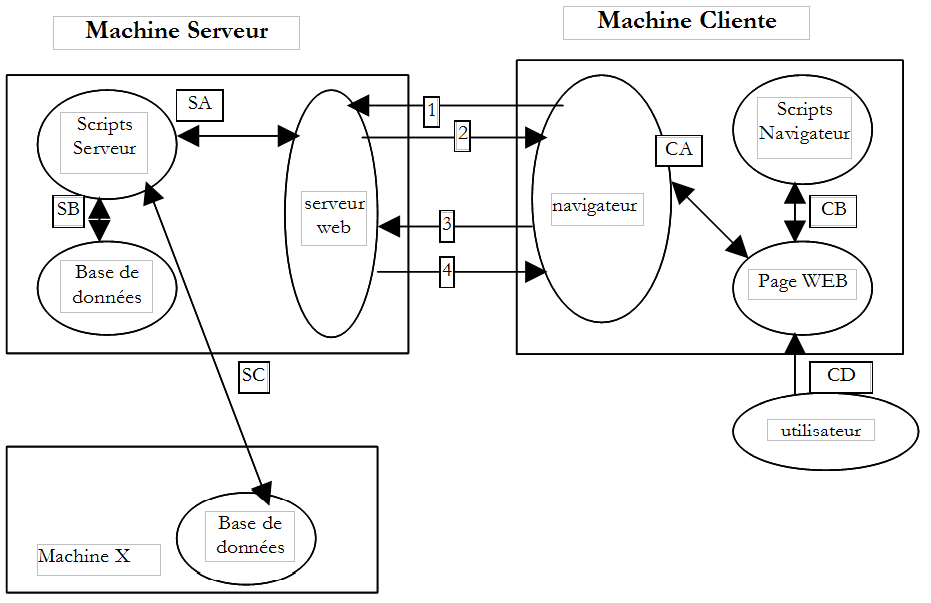
| NumÃĐro | RÃīle |
| 1 | Le navigateur demande une URL pour la 1re fois (http://machine/url). Auncun paramÃĻtre n'est passÃĐ. |
| 2 | Le serveur Web lui envoie la page Web de cette URL. Elle peut Être statique ou bien dynamiquement gÃĐnÃĐrÃĐe par un script serveur (SA) qui a pu utiliser le contenu de bases de donnÃĐes (SB, SC). Ici, le script dÃĐtectera que l'URL a ÃĐtÃĐ demandÃĐe sans passage de paramÃĻtres et gÃĐnÃĻrera la page WEB initiale. Le navigateur reçoit la page et l'affiche (CA). Des scripts cÃītÃĐ navigateur (CB) ont pu modifier la page initiale envoyÃĐe par le serveur. Ensuite par des interactions entre l'utilisateur (CD) et les scripts (CB) la page Web va Être modifiÃĐe. Les formulaires vont notamment Être remplis. |
| 3 | L'utilisateur valide les donnÃĐes du formulaire qui doivent alors Être envoyÃĐes au serveur web. Le navigateur redemande l'URL initiale ou une autre selon les cas et transmet en mÊme temps au serveur les valeurs du formulaire. Il peut utiliser pour ce faire deux mÃĐthodes appelÃĐes GET et POST. A rÃĐception de la demande du client, le serveur dÃĐclenche le script (SA) associÃĐ Ã l'URL demandÃĐe, script qui va dÃĐtecter les paramÃĻtres et les traiter. |
| 4 | Le serveur dÃĐlivre la page WEB construite par programme (SA, SB, SC). Cette ÃĐtape est identique à l'ÃĐtape 2 prÃĐcÃĐdente. Les ÃĐchanges se font dÃĐsormais selon les ÃĐtapes 2 et 3. |
II-C. Quelques ressources▲
Ci-dessous on trouvera une liste de ressources permettant d'installer et d'utiliser certains outils permettant de faire du dÃĐveloppement web. On trouvera en annexe, une aide à l'installation de ces outils.
| Serveur Apache | http://www.apache.org - Apache, Installation et Mise en Åuvre, O'Reilly |
| Serveur IIS, PWS | http://www.microsoft.com |
| PERL | http://www.activestate.com - Programmation en Perl, Larry Wall, O'Reilly - Applications CGI en Perl, Neuss et Vromans, O'Reilly - la documentation HTML livrÃĐe avec Active Perl |
| PHP | http://www.php.net - Prog. Web avec PHP, Lacroix, Eyrolles - Manuel d'utilisation de PHP rÃĐcupÃĐrable sur le site de PHP |
| VBSCRIPT, ASP | http://msdn.microsoft.com/scripting/vbscript/download/vbsdoc.exe http://msdn.microsoft.com/scripting/default.htm?/scripting/vbscript - Interface entre WEB et Base de donnÃĐes sous WinNT, Alex Homer, Eyrolles |
| JAVASCRIPT | http://msdn.microsoft.com/scripting/jscript/download/jsdoc.exe http://developer.netscape.com/docs/manuals/index.html |
| HTML | http://developer.netscape.com/docs/manuals/index.html |
| JAVA | http://www.sun.com - JAVA Servlets, Jason Hunter, O'Reilly - Programmation rÃĐseau avec Java, Elliotte Rusty Harold, O'Reilly - JDBC et Java, George Reese, O'reilly |
| Base de donnÃĐes | http://www.mysql.com http://www.oracle.com - Le manuel de MySQL est disponible sur le site de MySQL - Oracle 8i sous Linux, Gilles Briard, Eyrolles - Oracle 8i sous NT, Gilles Briard, Eyrolles |
II-D. Notations▲
Dans la suite, nous supposerons qu'un certain nombre d'outils ont ÃĐtÃĐ installÃĐs et adopterons les notations suivantes :
| notation | signification |
| <apache> | racine de l'arborescence du serveur apache |
| <apache-DocumentRoot> | racine des pages Web dÃĐlivrÃĐes par Apache. C'est sous cette racine que doivent se trouver les pages Web. Ainsi l'URL http://localhost/page1.htm correspond au fichier <apache-DocumentRoot>\page1.htm. |
| <apache-cgi-bin> | racine de l'arborescence liÃĐ Ã l'alias cgi-bin et oÃđ l'on peut placer des scripts CGI pour Apache. Ainsi l'URL http://localhost/cgi-bin/test1.pl correspond au fichier <apache-cgi-bin>\test1.pl. |
| <pws-DocumentRoot> | racine des pages Web dÃĐlivrÃĐes par PWS. C'est sous cette racine que doivent se trouver les pages Web. Ainsi l'URL http://localhost/page1.htm correspond au fichier <pws-DocumentRoot>\page1.htm. |
| <perl> | racine de l'arborescence du langage Perl. L'exÃĐcutable perl.exe se trouve en gÃĐnÃĐral dans <perl>\bin. |
| <php> | racine de l'arborescence du langage PHP. L'exÃĐcutable php.exe se trouve en gÃĐnÃĐral dans <php>. |
| <java> | racine de l'arborescence de java. Les exÃĐcutables liÃĐs à java se trouvent dans <java>\bin. |
| <tomcat> | racine du serveur Tomcat. On trouve des exemples de servlets dans <tomcat>\webapps\examples\servlets et des exemples de pages JSP dans <tomcat>\webbapps\examples\jsp |
On se reportera pour chacun de ces outils à l'annexe qui donne une aide pour leur installation.
II-E. Pages Web statiques, Pages Web dynamiques▲
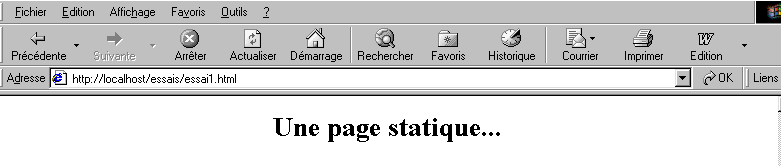
Une page statique est reprÃĐsentÃĐe par un fichier HTML. Une page dynamique est, elle, gÃĐnÃĐrÃĐe "Ã la volÃĐe" par le serveur web. Nous vous proposons dans ce paragraphe divers tests avec diffÃĐrents serveurs web et diffÃĐrents langages de programmation afin de montrer l'universalitÃĐ du concept web.
II-E-1. Page statique HTML (HyperText Markup Language)▲
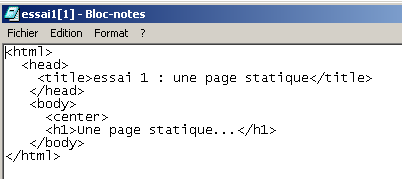
ConsidÃĐrons le code HTML suivant :
qui produit la page web suivante :
Les tests
- lancer le serveur Apache
- mettre le script essai1.html dans <apache-DocumentRoot>
- visualiser l'URL http://localhost/essai1.html avec un navigateur
- arrÊter le serveur Apache
- lancer le serveur PWS
- mettre le script essai1.html dans <pws-DocumentRoot
- visualiser l'URL http://localhost/essai1.html avec un navigateur
II-E-2. Une page ASP (Active Server Pages)▲
produit la page web suivante :

Le test
- lancer le serveur PWS
- mettre le script essai2.asp dans <pws-DocumentRoot>
- demander l'URL http://localhost/essai2.asp avec un navigateur
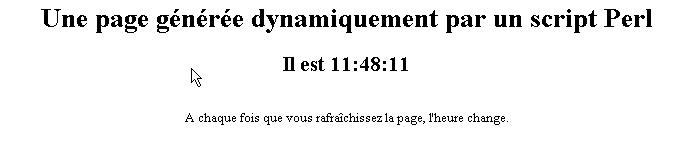
II-E-3. Un script PERL (Practical Extracting and Reporting Language)▲
La premiÃĻre ligne est le chemin de l'exÃĐcutable perl.exe. Il faut l'adapter si besoin est. Une fois exÃĐcutÃĐ par un serveur Web, le script produit la page suivante :
Le test
- serveur Web : Apache
- pour information, visualisez le fichier de configuration srm.conf ou httpd.conf selon la version d'Apache dans <apache>\confs et rechercher la ligne parlant de cgi-bin afin de connaÃŪtre le rÃĐpertoire <apache-cgi-bin> dans lequel placer essai3.pl.
- mettre le script essai3.pl dans <apache-cgi-bin>
- demander l'url http://localhost/cgi-bin/essai3.pl
A noter qu'il faut davantage de temps pour avoir la page perl que la page asp. Ceci parce que le script Perl est exÃĐcutÃĐ par un interprÃĐteur Perl qu'il faut charger avant qu'il puisse exÃĐcuter le script. Il ne reste pas en permanence en mÃĐmoire.
II-E-4. Un script PHP (Personal Home Page, HyperText Processor)▲
Le script prÃĐcÃĐdent produit la page web suivante :

Les tests
- consulter le fichier de configuration srm.conf ou httpd.conf d'Apache dans <Apache>\confs
- pour information, vÃĐrifier les lignes de configuration de php
- lancer le serveur Apache
- mettre essai4.php dans <apache-DocumentRoot>
- demander l'URL http://localhost/essai4.php
- lancer le serveur PWS
- pour information, vÃĐrifier la configuration de PWS Ã propos de php
- mettre essai4.php dans <pws-DocumentRoot>\php
- demander l'URL http://localhost/essai4.php
II-E-5. Un script JSP (Java Server Pages)▲
Une fois exÃĐcutÃĐ par le serveur web, ce script produit la page suivante :
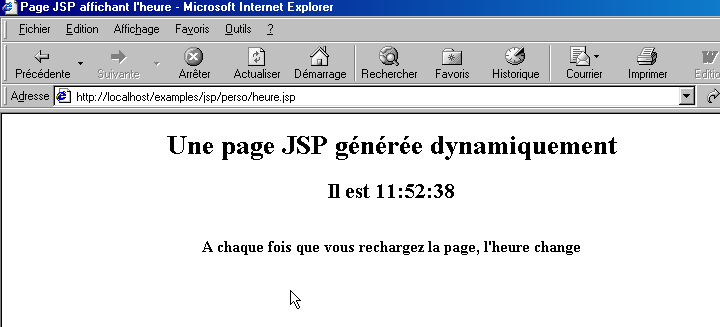
Les tests
- mettre le script heure.jsp dans <tomcat>\jakarta-tomcat\webapps\examples\jsp (Tomcat 3.x) ou dans <tomcat>\webapps\examples\jsp (Tomcat 4.x)
- lancer le serveur Tomcat
- demander l'URL http://localhost:8080/examples/jsp/heure.jsp
II-E-6. Conclusion▲
Les exemples prÃĐcÃĐdents ont montrÃĐ que :
- une page HTML pouvait Être gÃĐnÃĐrÃĐe dynamiquement par un programme. C'est tout le sens de la programmation Web.
- que les langages et les serveurs web utilisÃĐs pouvaient Être divers. Actuellement on observe les grandes tendances suivantes :
- les tandems Apache/PHP (Windows, Linux) et IIS/PHP (Windows)
- la technologie ASP.NET sur les plate-formes Windows qui associent le serveur IIS Ã un langage .NET (C#, VB.NETâĶ)
- la technologie des servlets Java et pages JSP fonctionnant avec diffÃĐrents serveurs (Tomcat, Apache, IIS) et sur diffÃĐrentes plate-formes (Windows, Linux). C'est cette deniÃĻre technologie qui sera plus particuliÃĻrement dÃĐveloppÃĐe dans ce document.
II-F. Scripts cÃītÃĐ navigateur▲
Une page HTML peut contenir des scripts qui seront exÃĐcutÃĐs par le navigateur. Les langages de script cÃītÃĐ navigateur sont nombreux. En voici quelques-uns :
| Langage | Navigateurs utilisables |
| Vbscript | IE |
| Javascript | IE, Netscape |
| PerlScript | IE |
| Java | IE, Netscape |
Prenons quelques exemples.
II-F-1. Une page Web avec un script Vbscript, cÃītÃĐ navigateur▲
La page HTML ci-dessus ne contient pas simplement du code HTML mais ÃĐgalement un programme destinÃĐ Ã ÃŠtre exÃĐcutÃĐ par le navigateur qui aura chargÃĐ cette page. Le code est le suivant :
Les balises <script></script> servent à dÃĐlimiter les scripts dans la page HTML. Ces scripts peuvent Être ÃĐcrits dans diffÃĐrents langages et c'est l'option language de la balise <script> qui indique le langage utilisÃĐ. Ici c'est VBScript. Nous ne chercherons pas à dÃĐtailler ce langage. Le script ci-dessus dÃĐfinit une fonction appelÃĐe rÃĐagir qui affiche un message. Quand cette fonction est-elle appelÃĐe ? C'est la ligne de code HTML suivante qui nous l'indique :
L'attribut onclick indique le nom de la fonction à appeler lorsque l'utilisateur cliquera sur le bouton OK. Lorsque le navigateur aura chargÃĐ cette page et que l'utilisateur cliquera sur le bouton OK, on aura la page suivante :
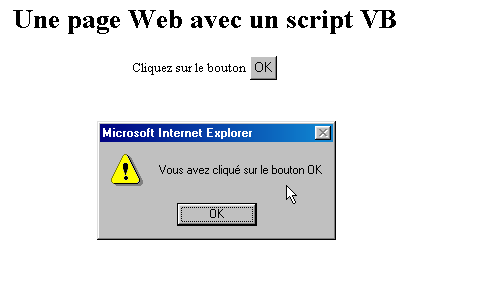
Les tests
Seul le navigateur IE est capable d'exÃĐcuter des scripts VBScript. Netscape nÃĐcessite des complÃĐments logiciels pour le faire. On pourra faire les tests suivants :
- serveur Apache
- script vbs1.html dans <apache-DocumentRoot>
- demander l'url http://localhost/vbs1.html avec le navigateur IE
- serveur PWS
- script vbs1.html dans <pws-DocumentRoot>
- demander l'url http://localhost/vbs1.html avec le navigateur IE
II-F-2. Une page Web avec un script Javascript, cÃītÃĐ navigateur▲
On a là quelque chose d'identique à la page prÃĐcÃĐdente si ce n'est qu'on a remplacÃĐ le langage VBScript par le langage Javascript. Celui-ci prÃĐsente l'avantage d'Être acceptÃĐ par les deux navigateurs IE et Netscape. Son exÃĐcution donne les mÊmes rÃĐsultats :
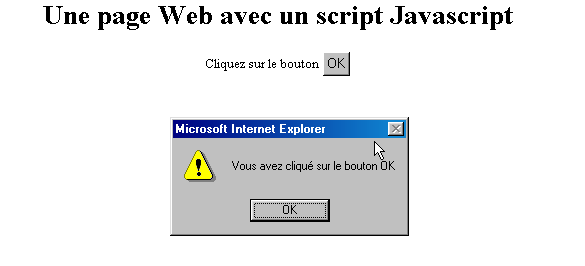
Les tests
- serveur Apache
- script js1.html dans <apache-DocumentRoot>
- demander l'url http://localhost/js1.html avec le navigateur IE ou Netscape
- serveur PWS
- script js1.html dans <pws-DocumentRoot>
- demander l'url http://localhost/js1.html avec le navigateur IE ou Netscape
II-G. Les ÃĐchanges client-serveur▲
Revenons à notre schÃĐma de dÃĐpart qui illustrait les acteurs d'une application web :
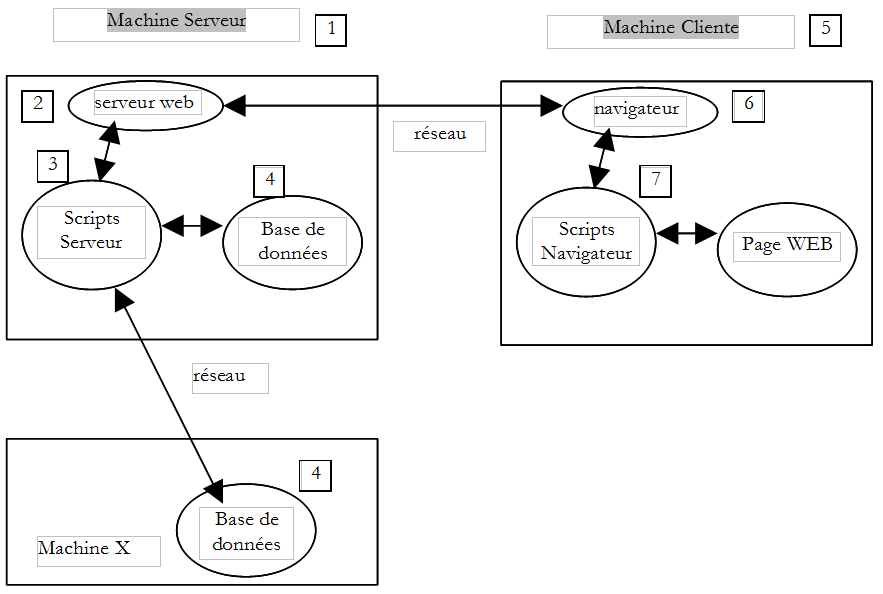
Nous nous intÃĐressons ici aux ÃĐchanges entre la machine cliente et la machine serveur. Ceux-ci se font au travers d'un rÃĐseau et il est bon de rappeler la structure gÃĐnÃĐrale des ÃĐchanges entre deux machines distantes.
II-G-1. Le modÃĻle OSI▲
Le modÃĻle de rÃĐseau ouvert appelÃĐ OSI (Open Systems Interconnection Reference Model) dÃĐfini par l'ISO (International Standards Organisation) dÃĐcrit un rÃĐseau idÃĐal oÃđ la communication entre machines peut Être reprÃĐsentÃĐe par un modÃĻle à sept couches :

Chaque couche reçoit des services de la couche infÃĐrieure et offre les siens à la couche supÃĐrieure. Supposons que deux applications situÃĐes sur des machines A et B diffÃĐrentes veulent communiquer : elles le font au niveau de la couche Application. Elles n'ont pas besoin de connaÃŪtre tous les dÃĐtails du fonctionnement du rÃĐseau : chaque application remet l'information qu'elle souhaite transmettre à la couche du dessous : la couche PrÃĐsentation. L'application n'a donc à connaÃŪtre que les rÃĻgles d'interfaçage avec la couche PrÃĐsentation. Une fois l'information dans la couche PrÃĐsentation, elle est passÃĐe selon d'autres rÃĻgles à la couche Session et ainsi de suite, jusqu'à ce que l'information arrive sur le support physique et soit transmise physiquement à la machine destination. Là , elle subira le traitement inverse de celui qu'elle a subi sur la machine expÃĐditeur.
A chaque couche, le processus expÃĐditeur chargÃĐ d'envoyer l'information, l'envoie à un processus rÃĐcepteur sur l'autre machine apartenant à la mÊme couche que lui. Il le fait selon certaines rÃĻgles que l'on appelle le protocole de la couche. On a donc le schÃĐma de communication final suivant :
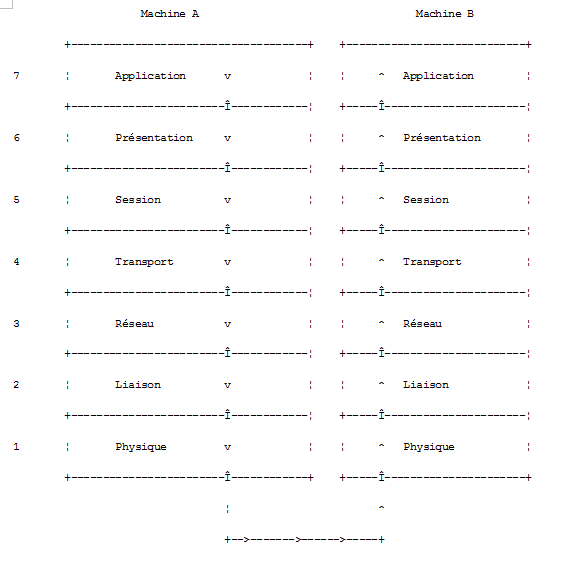
Le rÃīle des diffÃĐrentes couches est le suivant :
| Physique | Assure la transmission de bits sur un support physique. On trouve dans cette couche des ÃĐquipements terminaux de traitement des donnÃĐes (E.T.T.D.) tels que terminal ou ordinateur, ainsi que des ÃĐquipements de terminaison de circuits de donnÃĐes (E.T.C.D.) tels que modulateur/dÃĐmodulateur, multiplexeur, concentrateur. Les points d'intÃĐrÊt à ce niveau sont : .le choix du codage de l'information (analogique ou numÃĐrique) .le choix du mode de transmission (synchrone ou asynchrone). |
| Liaison de donnÃĐes | Masque les particularitÃĐs physiques de la couche Physique. DÃĐtecte et corrige les erreurs de transmission. |
| RÃĐseau | GÃĻre le chemin que doivent suivre les informations envoyÃĐes sur le rÃĐseau. On appelle cela le routage : dÃĐterminer la route à suivre par une information pour qu'elle arrive à son destinataire. |
| Transport | Permet la communication entre deux applications alors que les couches prÃĐcÃĐdentes ne permettaient que la communication entre machines. Un service fourni par cette couche peut Être le multiplexage : la couche transport pourra utiliser une mÊme connexion rÃĐseau (de machine à machine) pour transmettre des informations appartenant à plusieurs applications. |
| Session | On va trouver dans cette couche des services permettant à une application d'ouvrir et de maintenir une session de travail sur une machine distante. |
| PrÃĐsentation | Elle vise à uniformiser la reprÃĐsentation des donnÃĐes sur les diffÃĐrentes machines. Ainsi des donnÃĐes provenant d'une machine A, vont Être "habillÃĐes" par la couche PrÃĐsentation de la machine A, selon un format standard avant d'Être envoyÃĐes sur le rÃĐseau. Parvenues à la couche PrÃĐsentation de la machine destinatrice B qui les reconnaÃŪtra grÃĒce à leur format standard, elles seront habillÃĐes d'une autre façon afin que l'application de la machine B les reconnaisse. |
| Application | A ce niveau, on trouve les applications gÃĐnÃĐralement proches de l'utilisateur telles que la messagerie ÃĐlectronique ou le transfert de fichiers. |
II-G-2. Le modÃĻle TCP/IP▲
Le modÃĻle OSI est un modÃĻle idÃĐal. La suite de protocoles TCP/IP s'en approche sous la forme suivante :

- l'interface rÃĐseau (la carte rÃĐseau de l'ordinateur) assure les fonctions des couches 1 et 2 du modÃĻle OSI
- la couche IP (Internet Protocol) assure les fonctions de la couche 3 (rÃĐseau)
- la couche TCP (Transfer Control Protocol) ou UDP (User Datagram Protocol) assure les fonctions de la couche 4 (transport). Le protocole TCP s'assure que les paquets de donnÃĐes ÃĐchangÃĐs par les machines arrivent bien à destination. Si ce n'est pas les cas, il renvoie les paquets qui se sont ÃĐgarÃĐs. Le protocole UDP ne fait pas ce travail et c'est alors au dÃĐveloppeur d'applications de le faire. C'est pourquoi sur l'internet qui n'est pas un rÃĐseau fiable à 100%, c'est le protocole TCP qui est le plus utilisÃĐ. On parle alors de rÃĐseau TCP-IP.
- la couche Application recouvre les fonctions des niveaux 5 Ã 7 du modÃĻle OSI.
Les applications web se trouvent dans la couche Application et s'appuient donc sur les protocoles TCP-IP. Les couches Application des machines clientes et serveur s'ÃĐchangent des messages qui sont confiÃĐes aux couches 1 à 4 du modÃĻle pour Être acheminÃĐes à destination. Pour se comprendre, les couches application des deux machines doivent "parler" un mÊme langage ou protocole. Celui des applications Web s'appelle HTTP (HyperText Transfer Protocol). C'est un protocole de type texte, c.a.d. que les machines ÃĐchangent des lignes de texte sur le rÃĐseau pour se comprendre. Ces ÃĐchanges sont normalisÃĐs, c.a.d. que le client dispose d'un certain nombre de messages pour indiquer exactement ce qu'il veut au serveur et ce dernier dispose ÃĐgalement d'un certain nombre de messages pour donner au client sa rÃĐponse. Cet ÃĐchange de messages a la forme suivante :

Client --> Serveur
Lorsque le client fait sa demande au serveur web, il envoie
- des lignes de texte au format HTTP pour indiquer ce qu'il veut
- une ligne vide
- optionnellement un document
Serveur --> Client
Lorsque le serveur fait sa rÃĐponse au client, il envoie
- des lignes de texte au format HTTP pour indiquer ce qu'il envoie
- une ligne vide
- optionnellement un document
Les ÃĐchanges ont donc la mÊme forme dans les deux sens. Dans les deux cas, il peut y avoir envoi d'un document mÊme s'il est rare qu'un client envoie un document au serveur. Mais le protocole HTTP le prÃĐvoit. C'est ce qui permet par exemple aux abonnÃĐs d'un fournisseur d'accÃĻs de tÃĐlÃĐcharger des documents divers sur leur site personnel hÃĐbergÃĐ chez ce fournisseur d'accÃĻs. Les documents ÃĐchangÃĐs peuvent Être quelconques. Prenons un navigateur demandant une page web contenant des images :
- le navigateur se connecte au serveur web et demande la page qu'il souhaite. Les ressources demandÃĐes sont dÃĐsignÃĐes de façon unique par des URL (Uniform Resource Locator). Le navigateur n'envoie que des entÊtes HTTP et aucun document.
- le serveur lui rÃĐpond. Il envoie tout d'abord des entÊtes HTTP indiquant quel type de rÃĐponse il envoie. Ce peut Être une erreur si la page demandÃĐe n'existe pas. Si la page existe, le serveur dira dans les entÊtes HTTP de sa rÃĐponse qu'aprÃĻs ceux-ci il va envoyer un document HTML (HyperText Markup Language). Ce document est une suite de lignes de texte au format HTML. Un texte HTML contient des balises (marqueurs) donnant au navigateur des indications sur la façon d'afficher le texte.
- le client sait d'aprÃĻs les entÊtes HTTP du serveur qu'il va recevoir un document HTML. Il va analyser celui-ci et s'apercevoir peut-Être qu'il contient des rÃĐfÃĐrences d'images. Ces derniÃĻres ne sont pas dans le document HTML. Il fait donc une nouvelle demande au mÊme serveur web pour demander la premiÃĻre image dont il a besoin. Cette demande est identique à celle faite en 1, si ce n'est que la resource demandÃĐe est diffÃĐrente. Le serveur va traiter cette demande en envoyant à son client l'image demandÃĐe. Cette fois-ci, dans sa rÃĐponse, les entÊtes HTTP prÃĐciseront que le document envoyÃĐ est une image et non un document HTML.
- le client rÃĐcupÃĻre l'image envoyÃĐe. Les ÃĐtapes 3 et 4 vont Être rÃĐpÃĐtÃĐes jusqu'à ce que le client (un navigateur en gÃĐnÃĐral) ait tous les documents lui permettant d'afficher l'intÃĐgralitÃĐ de la page.
II-G-3. Le protocole HTTP▲
DÃĐcouvrons le protocole HTTP sur des exemples. Que s'ÃĐchangent un navigateur et un serveur web ?
II-G-3-a. La rÃĐponse d'un serveur HTTP▲
Nous allons dÃĐcouvrir ici comment un serveur web rÃĐpond aux demandes de ses clients. Le service Web ou service HTTP est un service TCP-IP qui travaille habituellement sur le port 80. Il pourrait travailler sur un autre port. Dans ce cas, le navigateur client serait obligÃĐ de prÃĐciser ce port dans l'URL qu'il demande. Une URL a la forme gÃĐnÃĐrale suivante :
protocole://machine[:port]/chemin/infos
avec
| protocole | http pour le service web. Un navigateur peut ÃĐgalement servir de client à des services ftp, news, telnet, .. |
| machine | nom de la machine oÃđ officie le service web |
| port | port du service web. Si c'est 80, on peut omettre le n° du port. C'est le cas le plus frÃĐquent |
| chemin | chemin dÃĐsignant la ressource demandÃĐe |
| infos | informations complÃĐmentaires donnÃĐes au serveur pour prÃĐciser la demande du client |
Que fait un navigateur lorsqu'un utilisateur demande le chargement d'une URLÂ ?
- il ouvre une communication TCP-IP avec la machine et le port indiquÃĐs dans la partie machine[:port] de l'URL. Ouvrir une communication TCP-IP, c'est crÃĐer un "tuyau" de communication entre deux machines. Une fois ce tuyau crÃĐÃĐ, toutes les informations ÃĐchangÃĐes entre les deux machines vont passer dedans. La crÃĐation de ce tuyau TCP-IP n'implique pas encore le protocole HTTP du Web.
- le tuyau TCP-IP crÃĐÃĐ, le client va faire sa demande au serveur Web et il va la faire en lui envoyant des lignes de texte (des commandes) au format HTTP. Il va envoyer au serveur la partie chemin/infos de l'URL
- le serveur lui rÃĐpondra de la mÊme façon et dans le mÊme tuyau
- l'un des deux partenaires prendra la dÃĐcision de fermer le tuyau. Cela dÃĐpend du protocole HTTP utilisÃĐ. Avec le protocole HTTP 1.0, le serveur ferme la connexion aprÃĻs chacune de ses rÃĐponses. Cela oblige un client qui doit faire plusieurs demandes pour obtenir les diffÃĐrents documents constituant une page web à ouvrir une nouvelle connexion à chaque demande, ce qui a un coÃŧt. Avec le protocole HTTP/1.1, le client peut dire au serveur de garder la connexion ouverte jusqu'à ce qu'il lui dise de la fermer. Il peut donc rÃĐcupÃĐrer tous les documents d'une page web avec une seule connexion et fermer lui-mÊme la connexion une fois le dernier document obtenu. Le serveur dÃĐtectera cette fermeture et fermera lui aussi la connexion.
Pour dÃĐcouvrir les ÃĐchanges entre un client et un serveur web, nous allons utiliser un client TCP gÃĐnÃĐrique. C'est un programme qui peut Être client de tout service ayant un protocole de communication à base de lignes de texte comme c'est le cas du protocole HTTP. Ces lignes de texte seront tapÃĐes par l'utilisateur au clavier. Cela nÃĐcessite qu'il connaisse le protocole de communication du service qu'il cherche à atteindre. La rÃĐponse du serveur est ensuite affichÃĐe à l'ÃĐcran. Le programme a ÃĐtÃĐ ÃĐcrit en Java et on le trouvera en annexe. On l'utilise ici dans une fenÊtre Dos sous windows et on l'appelle de la façon suivante :
java clientTCPgenerique machine port
avec
| machine | nom de la machine oÃđ officie le service à contacter |
| port | port oÃđ le service est dÃĐlivrÃĐ |
Avec ces deux informations, le programme va ouvrir une connexion TCP-IP avec la machine et le port dÃĐsignÃĐs. Cette connexion va servir aux ÃĐchanges de lignes de texte entre le client et le serveur web. Les lignes du client sont tapÃĐes par l'utilisateur au clavier et envoyÃĐes au serveur. Les lignes de texte renvoyÃĐes par le serveur comme rÃĐponse sont affichÃĐes à l'ÃĐcran. Un dialogue peut donc s'instaurer directement entre l'utilisateur au clavier et le serveur web. Essayons sur les exemples dÃĐjà prÃĐsentÃĐs. Nous avions crÃĐÃĐ la page HTML statique suivante :
que nous visualisons dans un navigateur :
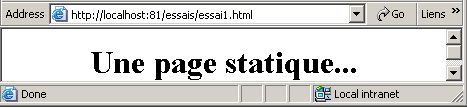
On voit que l'URL demandÃĐe est : http://localhost:81/essais/essai1.html. La machine du service web est donc localhost (=machine locale) et le port 81. Si on demande à voir le texte HTML de cette page Web (Affichage/Source) on retrouve le texte HTML initialement crÃĐÃĐ :
Maintenant utilisons notre client TCP gÃĐnÃĐrique pour demander la mÊme URL :
Au lancement du client par la commande java clientTCPgenerique localhost 81 un tuyau a ÃĐtÃĐ crÃĐÃĐ entre le programme et le serveur web opÃĐrant sur la mÊme machine (localhost) et sur le port 81. Les ÃĐchanges client-serveur au format HTTP peuvent commencer. Rappelons que ceux-ci ont trois composantes :
- entÊtes HTTP
- ligne vide
- donnÃĐes facultatives
Dans notre exemple, le client n'envoie qu'une demande:
GET /essais/essai1.html HTTP/1.0
Cette ligne a trois composantes :
| GET | commande HTTP pour demander une ressource. Il en existe d'autres : HEAD demande une ressource mais en se limitant aux entÊtes HTTP de la rÃĐponse du serveur. La ressource elle-mÊme n'est pas envoyÃĐe. PUT permet au client d'envoyer un document au serveur |
| /essais/essai1.html | ressource demandÃĐe |
| HTTP/1.0 | niveau du protocole HTTP utilisÃĐ. Ici le 1.0. Cela signifie que le serveur fermera la connexion dÃĻs qu'il aura envoyÃĐ sa rÃĐponse |
Les entÊtes HTTP doivent toujours Être suivis d'une ligne vide. C'est ce qui a ÃĐtÃĐ fait ici par le client. C'est comme cela que le client ou le serveur sait que la partie HTTP de l'ÃĐchange est terminÃĐ. Ici pour le client c'est terminÃĐ. Il n'a pas de document à envoyer. Commence alors la rÃĐponse du serveur composÃĐe dans notre exemple de toutes les lignes commençant par le signe <--. Il envoie d'abord une sÃĐrie d'entÊtes HTTP suivie d'une ligne vide :
| HTTP/1.1 200 OK | le serveur dit
|
| Date: âĶ | la date/heure de la rÃĐponse |
| Server: | le serveur s'identifie. Ici c'est un serveur Apache |
| Last-Modified: | date de derniÃĻre modification de la ressource demandÃĐe par le client |
| ETag: | âĶ |
| Accept-Ranges: bytes | unitÃĐ de mesure des donnÃĐes envoyÃĐes. Ici l'octet (byte) |
| Content-Length: 161 | nombre de bytes du document qui va Être envoyÃĐ aprÃĻs les entÊtes HTTP. Ce nombre est en fait la taille en octets du fichier essai1.html : E:\data\serge\web\essais>dir essai1.html 08/07/2002 10:00 161 essai1.html |
| Connection: close | le serveur dit qu'il fermera la connexion une fois le document envoyÃĐ |
| Content-type: text/html | le serveur dit qu'il va envoyer du texte (text) au format HTML (html). |
Le client reçoit ces entÊtes HTTP et sait maintenant qu'il va recevoir 161 octets reprÃĐsentant un document HTML. Le serveur envoie ces 161 octets immÃĐdiatement derriÃĻre la ligne vide qui signalait la fin des entÊtes HTTP :
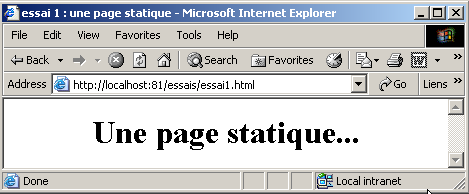
On reconnaÃŪt là , le fichier HTML construit initialement. Si notre client ÃĐtait un navigateur, aprÃĻs rÃĐception de ces lignes de texte, il les interprÃĐterait pour prÃĐsenter à l'utilisateur au clavier la page suivante :
Utilisons une nouvelle fois notre client TCP gÃĐnÃĐrique pour demander la mÊme ressource mais cette fois-ci avec la commande HEAD qui demande seulement les entÊtes de la rÃĐponse :
Nous obtenons le mÊme rÃĐsultat que prÃĐcÃĐdemment sans le document HTML. Notons que dans sa demande HEAD, le client a indiquÃĐ qu'il utilisait le protocole HTTP version 1.1. Cela l'oblige à envoyer un second entÊte HTTP prÃĐcisant le couple machine:port que le client veut interroger : Host: localhost:81.
Maintenant demandons une image aussi bien avec un navigateur qu'avec le client TCP gÃĐnÃĐrique. Tout d'abord avec un navigateur :
Le fichier univ01.gif a 3167 octets :
dos>dir univ01.gif
14/04/2000 13:37 3 167 univ01.gifUtilisons maintenant le client TCP gÃĐnÃĐrique :
On notera les points suivants dans la rÃĐponse du serveur :
| HEAD | nous ne demandons que les entÊtes HTTP de la ressource. En effet, une image est un fichier binaire et non un fichier texte et son affichage à l'ÃĐcran en tant que texte ne donne rien de lisible. |
| Content-Length: 3167 | c'est la taille du fichier univ01.gif |
| Content-Type: image/gif | le serveur indique à son client qu'il va lui envoyer un document de type image/gif, c.a.d. une image au format GIF. Si l'image avait ÃĐtÃĐ au format JPEG, le type du document aurait ÃĐtÃĐ image/jpeg. Les types des documents sont standardisÃĐs et sont appelÃĐs des types MIME (Multipurpose Mail Internet Extension). |
II-G-3-b. La demande d'un client HTTP▲
Maintenant, posons-nous la question suivante : si nous voulons ÃĐcrire un programme qui "parle" à un serveur web, quelles commandes doit-il envoyer au serveur web pour obtenir une ressource donnÃĐe ? Nous avons dans les exemples prÃĐcÃĐdents obtenu un dÃĐbut de rÃĐponse. Nous avons rencontrÃĐ trois commandes :
| GET ressource protocole | pour demander une ressource donnÃĐe selon une version donnÃĐe du protocole HTTP. Le serveur envoie une rÃĐponse au format HTTP suivie d'une ligne vide suivie de la ressource demandÃĐe |
| HEAD ressource protocole | idem si ce n'est qu'ici la rÃĐponse se limite aux entÊtes HTTP et de la ligne vide |
| host: machine:port | pour prÃĐciser (protocole HTTP 1.1) la machine et le port du serveur web interrogÃĐ |
Il existe d'autres commandes. Pour les dÃĐcouvrir, nous allons maintenant utiliser un serveur TCP gÃĐnÃĐrique. C'est un programme ÃĐcrit en Java et que vous trouverez lui aussi en annexe. Il est lancÃĐ par : java serveurTCPgenerique portEcoute, oÃđ portEcoute est le port sur lequel les clients doivent se connecter. Le programme serveurTCPgenerique
- affiche à l'ÃĐcran les commandes envoyÃĐes par les clients
- leur envoie comme rÃĐponse les lignes de texte tapÃĐes au clavier par un utilisateur. C'est donc ce dernier qui fait office de serveur. Dans notre exemple, l'utilisateur au clavier jouera le rÃīle d'un service web.
Simulons maintenant un serveur web en lançant notre serveur gÃĐnÃĐrique sur le port 88 :
Dos> java serveurTCPgenerique 88
Serveur gÃĐnÃĐrique lancÃĐ sur le port 88Prenons maintenant un navigateur et demandons l'URL http://localhost:88/exemple.html. Le navigateur va alors se connecter sur le port 88 de la machine localhost puis demander la page /exemple.html :
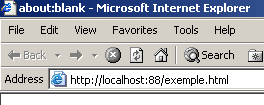
Regardons maintenant la fenÊtre de notre serveur qui affiche ce que le client lui a envoyÃĐ (certaines lignes spÃĐcifiques au fonctionnement du programme serveurTCPgenerique ont ÃĐtÃĐ omises par souci de simplification) :
Les lignes prÃĐcÃĐdÃĐes du signe <-- sont celles envoyÃĐes par le client. On dÃĐcouvre ainsi des entÊtes HTTP que nous n'avions pas encore rencontrÃĐs :
| Accept: | liste de types MIME de documents que le navigateur sait traiter. |
| Accept-language: | la langue acceptÃĐe de prÃĐfÃĐrence pour les documents. |
| Accept-Encoding: | le type d'encodage des documents que le navigateur sait traiter |
| User-Agent: | identitÃĐ du client |
| Connection: | Close : le serveur fermera la connexion aprÃĻs avoir donnÃĐ sa rÃĐponse Keep-Alive : la connexion restera ouverte aprÃĻs rÃĐception de la rÃĐponse du serveur. Cela permettra au navigateur de demander les autres documents nÃĐcessaires à la construction de la page sans avoir à recrÃĐer une connexion. |
Les entÊtes HTTP envoyÃĐs par le navigateur se terminent par une ligne vide comme attendu.
Elaborons une rÃĐponse à notre client. L'utilisateur au clavier est ici le vÃĐritable serveur et il peut ÃĐlaborer une rÃĐponse à la main. Rappelons-nous la rÃĐponse faite par un serveur Web dans un prÃĐcÃĐdent exemple :
Essayons d'ÃĐlaborer à la main (au clavier) une rÃĐponse analogue. Les lignes commençant par --> : sont envoyÃĐes au client :
La commande fin est propre au fonctionnement du programme serveurTCPgenerique. Elle arrÊte l'exÃĐcution du programme et clÃīt la connexion du serveur au client. Nous nous sommes limitÃĐs dans notre rÃĐponse aux entÊtes HTTP suivants :
Nous ne donnons pas la taille du fichier que nous allons envoyer (Content-Length) mais nous contentons de dire que nous allons fermer la connexion (Connection: close) aprÃĻs envoi de celui-ci. Cela est suffisant pour le navigateur. En voyant la connexion fermÃĐe, il saura que la rÃĐponse du serveur est terminÃĐe et affichera la page HTML qui lui a ÃĐtÃĐ envoyÃĐe. Cette derniÃĻre est la suivante :
Le navigateur affiche alors la page suivante :
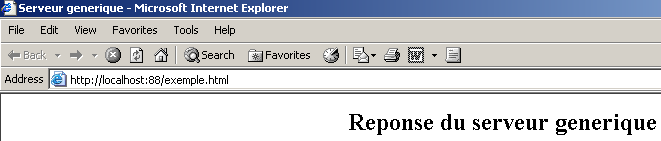
Si ci-dessus, on fait View/Source pour voir ce qu'a reçu le navigateur, on obtient :
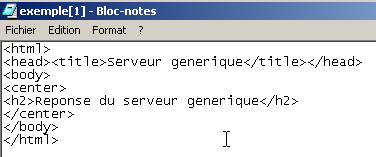
c'est-Ã -dire exactement ce qu'on a envoyÃĐ depuis le serveur gÃĐnÃĐrique.
II-H. Le langage HTML▲
Un navigateur Web peut afficher divers documents, le plus courant ÃĐtant le document HTML (HyperText Markup Language). Celui-ci est un texte formatÃĐ avec des balises de la forme <balise>texte</balise>. Ainsi le texte <B>important</B> affichera le texte important en gras. Il existe des balises seules telles que la balise <hr> qui affiche une ligne horizontale. Nous ne passerons pas en revue les balises que l'on peut trouver dans un texte HTML. Il existe de nombreux logiciels WYSIWYG permettant de construire une page web sans ÃĐcrire une ligne de code HTML. Ces outils gÃĐnÃĻrent automatiquement le code HTML d'une mise en page faite à l'aide de la souris et de contrÃīles prÃĐdÃĐfinis. On peut ainsi insÃĐrer (avec la souris) dans la page un tableau puis consulter le code HTML gÃĐnÃĐrÃĐ par le logiciel pour dÃĐcouvrir les balises à utiliser pour dÃĐfinir un tableau dans une page Web. Ce n'est pas plus compliquÃĐ que cela. Par ailleurs, la connaissance du langage HTML est indispensable puisque les applications web dynamiques doivent gÃĐnÃĐrer elles-mÊmes le code HTML à envoyer aux clients web. Ce code est gÃĐnÃĐrÃĐ par programme et il faut bien sÃŧr savoir ce qu'il faut gÃĐnÃĐrer pour que le client ait la page web qu'il dÃĐsire.
Pour rÃĐsumer, il n'est nul besoin de connaÃŪtre la totalitÃĐ du langage HTML pour dÃĐmarrer la programmation Web. Cependant cette connaissance est nÃĐcessaire et peut Être acquise au travers de l'utilisation de logiciels WYSIWYG de construction de pages Web tels que Word, FrontPage, DreamWeaver et des dizaines d'autres. Une autre façon de dÃĐcouvrir les subtilitÃĐs du langage HTML est de parcourir le web et d'afficher le code source des pages qui prÃĐsentent des caractÃĐristiques intÃĐressantes et encore inconnues pour vous.
II-H-1. Un exemple▲
ConsidÃĐrons l'exemple suivant, crÃĐÃĐ avec FrontPage Express, un outil gratuit livrÃĐ avec Internet Explorer. Le code gÃĐnÃĐrÃĐ par Frontpage a ÃĐtÃĐ ici ÃĐpurÃĐ. Cet exemple prÃĐsente quelques ÃĐlÃĐments qu'on peut trouver dans un document web tels que :
- un tableau
- une image
- un lien
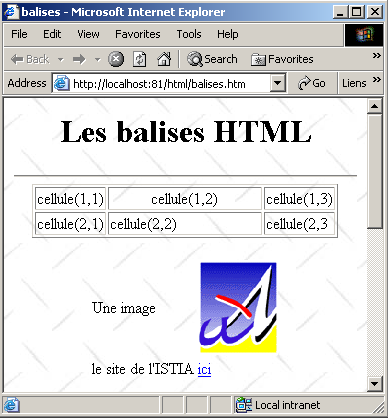
Un document HTML a la forme gÃĐnÃĐrale suivante :
L'ensemble du document est encadrÃĐ par les balises <html>âĶ</html>. Il est formÃĐ de deux parties :
- <head>âĶ</head>Â : c'est la partie non affichable du document. Elle donne des renseignements au navigateur qui va afficher le document. On y trouve souvent la balise <title>âĶ</title> qui fixe le texte qui sera affichÃĐ dans la barre de titre du navigateur. On peut y trouver d'autres balises notamment des balises dÃĐfinissant les mots clÃĐs du document, mot clÃĐs utilisÃĐs ensuite par les moteurs de recherche. On peut trouver ÃĐgalement dans cette partie des scripts, ÃĐcrits le plus souvent en javascript ou vbscript et qui seront exÃĐcutÃĐs par le navigateur.
- <body attributs>âĶ</body> : c'est la partie qui sera affichÃĐe par le navigateur. Les balises HTML contenues dans cette partie indiquent au navigateur la forme visuelle "souhaitÃĐe" pour le document. Chaque navigateur va interprÃĐter ces balises à sa façon. Deux navigateurs peuvent alors visualiser diffÃĐremment un mÊme document web. C'est gÃĐnÃĐralement l'un des casse-tÊtes des concepteurs web.
Le code HTML de notre document exemple est le suivant :
Ont ÃĐtÃĐ mis en relief dans le code les seuls points qui nous intÃĐressent :
| ElÃĐment | balises et exemples HTML |
| titre du document | <title>balises</title> balises apparaÃŪtra dans la barre de titre du navigateur qui affichera le document |
| barre horizontale | <hr>Â : affiche un trait horizontal |
| tableau | <table attributs>âĶ.</table> : pour dÃĐfinir le tableau <tr attributs>âĶ</tr> : pour dÃĐfinir une ligne <td attributs>âĶ</td> : pour dÃĐfinir une cellule exemples : <table border="1">âĶ</table> : l'attribut border dÃĐfinit l'ÃĐpaisseur de la bordure du tableau <td valign="middle" align="center" width="150">cellule(1,2)</td> : dÃĐfinit une cellule dont le contenu sera cellule(1,2). Ce contenu sera centrÃĐ verticalement (valign="middle") et horizontalement (align="center"). La cellule aura une largeur de 150 pixels (width="150") |
| image | <img border="0" src="/images/univ01.gif" width="80" height="95">Â : dÃĐfinit une image sans bordure (border=0"), de hauteur 95 pixels (height="95"), de largeur 80 pixels (width="80") et dont le fichier source est /images/univ01.gif sur le serveur web (src="/images/univ01.gif"). Ce lien se trouve sur un document web qui a ÃĐtÃĐ obtenu avec l'URL http://localhost:81/html/balises.htm. Aussi, le navigateur demandera-t-il l'URL http://localhost:81/images/univ01.gif pour avoir l'image rÃĐfÃĐrencÃĐe ici. |
| lien | <a href="http://istia.univ-angers.fr">ici</a>Â : fait que le texte ici sert de lien vers l'URL http://istia.univ-angers.fr. |
| fond de page | <body background="/images/standard.jpg"> : indique que l'image qui doit servir de fond de page se trouve à l'URL /images/standard.jpg du serveur web. Dans le contexte de notre exemple, le navigateur demandera l'URL http://localhost:81/images/standard.jpg pour obtenir cette image de fond. |
On voit dans ce simple exemple que pour construire l'intÃĐralitÃĐ du document, le navigateur doit faire trois requÊtes au serveur :
- http://localhost:81/html/balises.htm pour avoir le source HTML du document
- http://localhost:81/images/univ01.gif pour avoir l'image univ01.gif
- http://localhost:81/images/standard.jpg pour obtenir l'image de fond standard.jpg
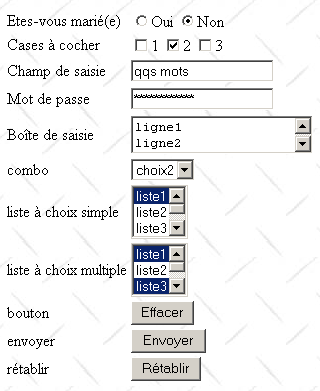
L'exemple suivant prÃĐsente un formulaire Web crÃĐÃĐ lui aussi avec FrontPage.
Le code HTML gÃĐnÃĐrÃĐ par FrontPage et un peu ÃĐpurÃĐ est le suivant :
L'association contrÃīle visuel <--> balise HTML est le suivant :
| ContrÃīle | balise HTML |
| formulaire | <form method="POST" > |
| champ de saisie | <input type="text" name="txtSaisie" size="20" value="qqs mots"> |
| champ de saisie cachÃĐe | <input type="password" name="txtMdp" size="20" value="unMotDePasse"> |
| champ de saisie multilignes | <textarea rows="2" name="areaSaisie" cols="20"> ligne1 ligne2 ligne3 </textarea> |
| boutons radio | <input type="radio" value="Oui" name="R1">Oui <input type="radio" name="R1" value="non" checked>Non |
| cases à cocher | <input type="checkbox" name="C1" value="un">1 <input type="checkbox" name="C2" value="deux" checked>2 <input type="checkbox" name="C3" value="trois">3 |
| Combo | <select size="1" name="cmbValeurs"> <option>choix1</option> <option selected>choix2</option> <option>choix3</option> </select> |
| liste à sÃĐlection unique | <select size="3" name="lst1"> <option selected>liste1</option> <option>liste2</option> <option>liste3</option> <option>liste4</option> <option>liste5</option> </select> |
| liste à sÃĐlection multiple | <select size="3" name="lst2" multiple> <option>liste1</option> <option>liste2</option> <option selected>liste3</option> <option>liste4</option> <option>liste5</option> </select> |
| bouton de type submit | <input type="submit" value="Envoyer" name="cmdRenvoyer"> |
| bouton de type reset | <input type="reset" value="RÃĐtablir" name="cmdRÃĐtablir"> |
| bouton de type button | <input type="button" value="Effacer" name="cmdEffacer" onclick="effacer()"> |
Passons en revue ces diffÃĐrents contrÃīles.
II-H-1-a. Le formulaire▲
| formulaire | <form method="POST" > |
| balise HTML | <form name="âĶ" method="âĶ" action="âĶ">âĶ</form> |
| attributs | name="frmexemple" : nom du formulaire method="âĶ" : mÃĐthode utilisÃĐe par le navigateur pour envoyer au serveur web les valeurs rÃĐcoltÃĐes dans le formulaire action="âĶ" : URL à laquelle seront envoyÃĐes les valeurs rÃĐcoltÃĐes dans le formulaire. Un formulaire web est entourÃĐ des balises <form>âĶ</form>. Le formulaire peut avoir un nom (name="xx"). C'est le cas pour tous les contrÃīles qu'on peut trouver dans un formulaire. Ce nom est utile si le document web contient des scripts qui doivent rÃĐfÃĐrencer des ÃĐlÃĐments du formulaire. Le but d'un formulaire est de rassembler des informations donnÃĐes par l'utilisateur au clavier/souris et d'envoyer celles-ci à une URL de serveur web. Laquelle ? Celle rÃĐfÃĐrencÃĐe dans l'attribut action="URL". Si cet attribut est absent, les informations seront envoyÃĐes à l'URL du document dans lequel se trouve le formulaire. Ce serait le cas dans l'exemple ci-dessus. Jusqu'à maintenant, nous avons toujours vu le client web comme "demandant" des informations à un serveur web, jamais lui "donnant" des informations. Comment un client web fait-il pour donner des informations (celles contenues dans le formulaire) à un serveur web ? Nous y reviendrons dans le dÃĐtail un peu plus loin. Il peut utiliser deux mÃĐthodes diffÃĐrentes appelÃĐes POST et GET. L'attribut method="mÃĐthode", avec mÃĐthode ÃĐgale à GET ou POST, de la balise <form> indique au navigateur la mÃĐthode à utiliser pour envoyer les informations recueillies dans le formulaire à l'URL prÃĐcisÃĐe par l'attribut action="URL". Lorsque l'attribut method n'est pas prÃĐcisÃĐ, c'est la mÃĐthode GET qui est prise par dÃĐfaut. |
II-H-1-b. Champ de saisie▲
![]()
![]()
| champ de saisie | <input type="text" name="txtSaisie" size="20" value="qqs mots"> <input type="password" name="txtMdp" size="20" value="unMotDePasse"> |
| balise HTML | <input type="âĶ" name="âĶ" size=".." value=".."> La balise input existe pour divers contrÃīles. C'est l'attribut type qui permet de diffÃĐrentier ces diffÃĐrents contrÃīles entre eux. |
| attributs | type="text" : prÃĐcise que c'est un champ de saisie type="password" : les caractÃĻres prÃĐsents dans le champ de saisie sont remplacÃĐs par des caractÃĻres *. C'est la seule diffÃĐrence avec le champ de saisie normal. Ce type de contrÃīle convient pour la saisie des mots de passe. size="20" : nombre de caractÃĻres visibles dans le champ - n'empÊche pas la saisie de davantage de caractÃĻres name="txtSaisie" : nom du contrÃīle value="qqs mots" : texte qui sera affichÃĐ dans le champ de saisie. |
II-H-1-c. Champ de saisie multilignes▲
![]()
| champ de saisie multilignes |
<textarea rows="2" name="areaSaisie" cols="20">
ligne1 ligne2 ligne3 </textarea> |
| balise HTML | <textarea âĶ>texte</textarea> affiche une zone de saisie multilignes avec au dÃĐpart texte dedans |
| attributs | rows="2"Â : nombre de lignes cols="'20"Â : nombre de colonnes name="areaSaisie"Â : nom du contrÃīle |
II-H-1-d. Boutons radio▲
![]()
| boutons radio | <input type="radio" value="Oui" name="R1">Oui <input type="radio" name="R1" value="non" checked>Non |
| balise HTML | <input type="radio" attribut2="valeur2" âĶ.>texte affiche un bouton radio avec texte à cÃītÃĐ. |
| attributs | name="radio" : nom du contrÃīle. Les boutons radio portant le mÊme nom forment un groupe de boutons exclusifs les uns des autres : on ne peut cocher que l'un d'eux. value="valeur" : valeur affectÃĐe au bouton radio. Il ne faut pas confondre cette valeur avec le texte affichÃĐ Ã cÃītÃĐ du bouton radio. Celui-ci n'est destinÃĐ qu'à l'affichage. checked : si ce mot clÃĐ est prÃĐsent, le bouton radio est cochÃĐ, sinon il ne l'est pas. |
II-H-1-e. Cases à cocher▲
| cases à cocher | <input type="checkbox" name="C1" value="un">1 <input type="checkbox" name="C2" value="deux" checked>2 <input type="checkbox" name="C3" value="trois">3 |
![]()
| balise HTML | <input type="checkbox" attribut2="valeur2" âĶ.>texte affiche une case à cocher avec texte à cÃītÃĐ. |
| attributs | name="C1" : nom du contrÃīle. Les cases à cocher peuvent porter ou non le mÊme nom. Les cases portant le mÊme nom forment un groupe de cases associÃĐes. value="valeur" : valeur affectÃĐe à la case à cocher. Il ne faut pas confondre cette valeur avec le texte affichÃĐ Ã cÃītÃĐ du bouton radio. Celui-ci n'est destinÃĐ qu'à l'affichage. checked : si ce mot clÃĐ est prÃĐsent, le bouton radio est cochÃĐ, sinon il ne l'est pas. |
II-H-1-f. Liste dÃĐroulante (combo)▲
| Combo | <select size="1" name="cmbValeurs"> <option>choix1</option> <option selected>choix2</option> <option>choix3</option> </select> |
![]()
| balise HTML | <select size=".." name=".."> <option [selected]>âĶ</option> âĶ </select> affiche dans une liste les textes compris entre les balises <option>âĶ</option> |
| attributs | name="cmbValeurs" : nom du contrÃīle. size="1" : nombre d'ÃĐlÃĐments de liste visibles. size="1" fait de la liste l'ÃĐquivalent d'un combobox. selected : si ce mot clÃĐ est prÃĐsent pour un ÃĐlÃĐment de liste, ce dernier apparaÃŪt sÃĐlectionnÃĐ dans la liste. Dans notre exemple ci-dessus, l'ÃĐlÃĐment de liste choix2 apparaÃŪt comme l'ÃĐlÃĐment sÃĐlectionnÃĐ du combo lorsque celui-ci est affichÃĐ pour la premiÃĻre fois. |
II-H-1-g. Liste à sÃĐlection unique▲
| liste à sÃĐlection unique | <select size="3" name="lst1"> <option selected>liste1</option> <option>liste2</option> <option>liste3</option> <option>liste4</option> <option>liste5</option> </select> |
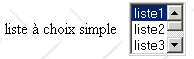
| balise HTML | <select size=".." name=".."> <option [selected]>âĶ</option> âĶ </select> affiche dans une liste les textes compris entre les balises <option>âĶ</option> |
| attributs | les mÊmes que pour la liste dÃĐroulante n'affichant qu'un ÃĐlÃĐment. Ce contrÃīle ne diffÃĻre de la liste dÃĐroulante prÃĐcÃĐdente que par son attribut size>1. |
II-H-1-h. Liste à sÃĐlection multiple▲
| liste à sÃĐlection unique | <select size="3" name="lst2" multiple> <option selected>liste1</option> <option>liste2</option> <option selected>liste3</option> <option>liste4</option> <option>liste5</option> </select> |
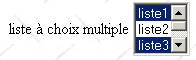
| balise HTML | <select size=".." name=".." multiple> <option [selected]>âĶ</option> âĶ </select> affiche dans une liste les textes compris entre les balises <option>âĶ</option> |
| attributs | multiple : permet la sÃĐlection de plusieurs ÃĐlÃĐments dans la liste. Dans l'exemple ci-dessus, les ÃĐlÃĐments liste1 et liste3 sont tous deux sÃĐlectionnÃĐs. |
II-H-1-i. Bouton de type button▲
| bouton de type button | <input type="button" value="Effacer" name="cmdEffacer" onclick="effacer()"> |
![]()
| balise HTML | <input type="button" value="âĶ" name="âĶ" onclick="effacer()" âĶ.> |
| attributs | type="button" : dÃĐfinit un contrÃīle bouton. Il existe deux autres types de bouton, les types submit et reset. value="Effacer" : le texte affichÃĐ sur le bouton onclick="fonction()" : permet de dÃĐfinir une fonction à exÃĐcuter lorsque l'utilisateur clique sur le bouton. Cette fonction fait partie des scripts dÃĐfinis dans le document web affichÃĐ. La syntaxe prÃĐcÃĐdente est une syntaxe javascript. Si les scripts sont ÃĐcrits en vbscript, il faudrait ÃĐcrire onclick="fonction" sans les parenthÃĻses. La syntaxe devient identique s'il faut passer des paramÃĻtres à la fonction : onclick="fonction(val1, val2,âĶ)" Dans notre exemple, un clic sur le bouton Effacer appelle la fonction javascript effacer suivante : <script language="JavaScript"> function effacer(){ alert("Vous avez cliquÃĐ sur le bouton Effacer"); }//effacer </script> La fonction effacer affiche un message : 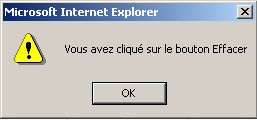 |
II-H-1-j. Bouton de type submit▲
| bouton de type submit | <input type="submit" value="Envoyer" name="cmdRenvoyer"> |
![]()
| balise HTML | <input type="submit" value="Envoyer" name="cmdRenvoyer"> |
| attributs | type="submit" : dÃĐfinit le bouton comme un bouton d'envoi des donnÃĐes du formulaire au serveur web. Lorsque le client va cliquer sur ce bouton, le navigateur va envoyer les donnÃĐes du formulaire à l'URL dÃĐfinie dans l'attribut action de la balise <form> selon la mÃĐthode dÃĐfinie par l'attribut method de cette mÊme balise. value="Envoyer" : le texte affichÃĐ sur le bouton |
II-H-1-k. Bouton de type reset▲
| bouton de type reset | <input type="reset" value="RÃĐtablir" name="cmdRÃĐtablir"> |
![]()
| balise HTML | <input type="reset" value="RÃĐtablir" name="cmdRÃĐtablir"> |
| attributs | type="reset" : dÃĐfinit le bouton comme un bouton de rÃĐinitialisation du formulaire. Lorsque le client va cliquer sur ce bouton, le navigateur va remettre le formulaire dans l'ÃĐtat oÃđ il l'a reçu. value="RÃĐtablir" : le texte affichÃĐ sur le bouton |
II-H-1-l. Champ cachÃĐ▲
| champ cachÃĐ | <input type="hidden" name="secret" value="uneValeur"> |
| balise HTML | <input type="hidden" name="âĶ" value="âĶ"> |
| attributs | type="hidden" : prÃĐcise que c'est un champ cachÃĐ. Un champ cachÃĐ fait partie du formulaire mais n'est pas prÃĐsentÃĐ Ã l'utilisateur. Cependant, si celui-ci demandait à son navigateur l'affichage du code source, il verrait la prÃĐsence de la balise <input type="hidden" value="âĶ"> et donc la valeur du champ cachÃĐ. value="uneValeur" : valeur du champ cachÃĐ. Quel est l'intÃĐrÊt du champ cachÃĐ ? Cela peut permettre au serveur web de garder des informations au fil des requÊtes d'un client. ConsidÃĐrons une application d'achats sur le web. Le client achÃĻte un premier article art1 en quantitÃĐ q1 sur une premiÃĻre page d'un catalogue puis passe à une nouvelle page du catalogue. Pour se souvenir que le client a achetÃĐ q1 articles art1, le serveur peut mettre ces deux informations dans un champ cachÃĐ du formulaire web de la nouvelle page. Sur cette nouvelle page, le client achÃĻte q2 articles art2. Lorsque les donnÃĐes de ce second formulaire vont Être envoyÃĐes au serveur (submit), celui-ci va non seulement recevoir l'information (q2,art2) mais aussi (q1,art1) qui fait partie ÃĐgalement partie du formulaire en tant que champ cachÃĐ non modifiable par l'utilisateur. Le serveur web va alors mettre dans un nouveau champ cachÃĐ les informations (q1,art1) et (q2,art2) et envoyer une nouvelle page de catalogue. Et ainsi de suite. |
II-H-2. Envoi à un serveur web par un client web des valeurs d'un formulaire▲
Nous avons dit dans l'ÃĐtude prÃĐcÃĐdente que le client web disposait de deux mÃĐthodes pour envoyer à un serveur web les valeurs d'un formulaire qu'il a affichÃĐ : les mÃĐthodes GET et POST. Voyons sur un exemple la diffÃĐrence entre les deux mÃĐthodes. Nous reprenons l'exemple prÃĐcÃĐdent et le traitons de la façon suivante :
- un navigateur demande l'URL de l'exemple à un serveur web
- une fois le formulaire obtenu, nous le remplissons
- avant d'envoyer les valeurs du formulaire au serveur web en cliquant sur le bouton Envoyer de type submit, nous arrÊtons le serveur web et le remplaçons par le serveur TCP gÃĐnÃĐrique dÃĐjà utilisÃĐ prÃĐcÃĐdemment. Rappelons que celui-ci affiche à l'ÃĐcran les lignes de texte que lui envoie le client web. Ainsi nous verrons ce qu'envoie exactement le navigateur.
Le formulaire est rempli de la façon suivante :
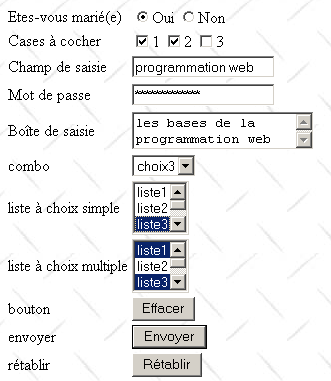
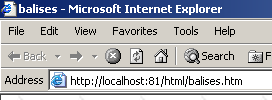
L'URL utilisÃĐe pour ce document est la suivante :
II-H-2-a. MÃĐthode GET▲
Le document HTML est programmÃĐ pour que le navigateur utilise la mÃĐthode GET pour envoyer les valeurs du formulaire au serveur web. Nous avons donc ÃĐcrit :
<form method="GET" >Nous arrÊtons le serveur web et lançons notre serveur TCP gÃĐnÃĐrique sur le port 81 :
dos>java serveurTCPgenerique 81
Serveur gÃĐnÃĐrique lancÃĐ sur le port 81Maintenant, nous revenons dans notre navigateur pour envoyer les donnÃĐes du formulaire au serveur web à l'aide du bouton Envoyer :
Voici alors ce que reçoit le serveur TCP gÃĐnÃĐrique :
Tout est dans le premier entÊte HTTP envoyÃĐ par le navigateur :
On voit qu'il est beaucoup plus complexe que ce qui avait ÃĐtÃĐ rencontrÃĐ jusqu'à maintenant. On y retrouve la syntaxe GET URL HTTP/1.1 mais sous une forme particuliÃĻre GET URL?param1=valeur1¶m2=valeur2&âĶ HTTP/1.1 oÃđ les parami sont les noms des contrÃīles du formulaire web et valeuri les valeurs qui leur sont associÃĐes. Examinons-les de plus prÃĻs. Nous prÃĐsentons ci-dessous un tableau à trois colonnes :
- colonne 1Â : reprend la dÃĐfinition d'un contrÃīle HTML de l'exemple
- colonne 2Â : donne l'affichage de ce contrÃīle dans un navigateur
- colonne 3 : donne la valeur envoyÃĐe au serveur par le navigateur pour le contrÃīle de la colonne 1 sous la forme qu'elle a dans la requÊte GET de l'exemple
| contrÃīle HTML | visuel | valeur(s) renvoyÃĐe(s) |
<input type="radio" value="Oui" name="R1">Oui <input type="radio" name="R1" value="non" checked>Non |
|
- la valeur de l'attribut value du bouton radio cochÃĐ par l'utilisateur. |
| <input type="checkbox" name="C1" value="un">1 <input type="checkbox" name="C2" value="deux" checked>2 <input type="checkbox" name="C3" value="trois">3 |
|
C1=un C2=deux - valeurs des attributs value des cases cochÃĐes par l'utilisateur |
| <input type="text" name="txtSaisie" size="20" value="qqs mots"> |
|
txtSaisie=programmation+web - texte tapÃĐ par l'utilisateur dans le champ de saisie. Les espaces ont ÃĐtÃĐ remplacÃĐs par le signe + |
| <input type="password" name="txtMdp" size="20" value="unMotDePasse"> |
|
txtMdp=ceciestsecret - texte tapÃĐ par l'utilisateur dans le champ de saisie |
| <textarea rows="2" name="areaSaisie" cols="20"> ligne1 ligne2 ligne3 </textarea> |
|
areaSaisie=les+bases+de+la%0D%0A programmation+web - texte tapÃĐ par l'utilisateur dans le champ de saisie. %OD%OA est la marque de fin de ligne. Les espaces ont ÃĐtÃĐ remplacÃĐs par le signe + |
| <select size="1" name="cmbValeurs"> <option>choix1</option> <option selected>choix2</option> <option>choix3</option> </select> |
|
cmbValeurs=choix3 - valeur choisie par l'utilisateur dans la liste à sÃĐlection unique |
| <select size="3" name="lst1"> <option selected>liste1</option> <option>liste2</option> <option>liste3</option> <option>liste4</option> <option>liste5</option> </select> |
|
lst1=liste3 - valeur choisie par l'utilisateur dans la liste à sÃĐlection unique |
| <select size="3" name="lst2" multiple> <option selected>liste1</option> <option>liste2</option> <option selected>liste3</option> <option>liste4</option> <option>liste5</option> </select> |
|
lst2=liste1 lst2=liste3 - valeurs choisies par l'utilisateur dans la liste à sÃĐlection multiple |
| <input type="submit" value="Envoyer" name="cmdRenvoyer"> |  | cmdRenvoyer=Envoyer - nom et attribut value du bouton qui a servi à envoyer les donnÃĐes du formulaire au serveur |
| <input type="hidden" name="secret" value="uneValeur"> | Â | secret=uneValeur - attribut value du champ cachÃĐ |
Refaisons la mÊme chose mais cette fois-ci en gardant le serveur web pour ÃĐlaborer la rÃĐponse et voyons quelle est cette derniÃĻre. La page renvoyÃĐe par le serveur Web est la suivante :
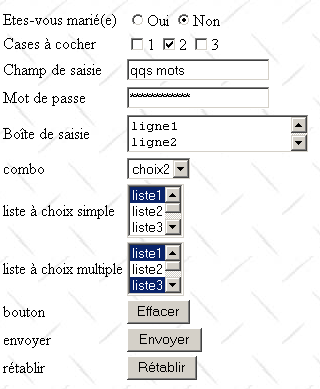
C'est exactement la mÊme que celle reçue initialement avant le remplissage du formulaire. Pour comprendre pourquoi, il faut regarder de nouveau l'URL demandÃĐe par le navigateur lorsque l'utilisateur appuie sur le bouton Envoyer :
L'URL demandÃĐe est /html/balises.htm. On passe de plus à cette URL des valeurs qui sont celles du formulaire. Pour l'instant, l'URL /html/balises.htm qui est une page statique n'utilise pas ces valeurs. Si bien que le GET prÃĐcÃĐdent est ÃĐquivalent Ã
et c'est pourquoi le serveur nous a renvoyÃĐ de nouveau la page initiale. On remarquera que le navigateur affiche bien lui l'URL complÃĻte qui a ÃĐtÃĐ demandÃĐe :

II-H-2-b. MÃĐthode POST▲
Le document HTML est programmÃĐ pour que le navigateur utilise maintenant la mÃĐthode POST pour envoyer les valeurs du formulaire au serveur web :
Nous arrÊtons le serveur web et lançons le serveur TCP gÃĐnÃĐrique (dÃĐjà rencontrÃĐ mais un peu modifiÃĐ pour l'occasion) sur le port 81 :
Maintenant, nous revenons dans notre navigateur pour envoyer les donnÃĐes du formulaire au serveur web à l'aide du bouton Envoyer :
Voici alors ce que reçoit le serveur TCP gÃĐnÃĐrique :
Par rapport à ce que nous connaissons dÃĐjà , nous notons les changements suivants dans la requÊte du navigateur :
- L'entÊte HTTP initial n'est plus GET mais POST. La syntaxe est POST URL HTTP/1.1 oÃđ URL est l'URL demandÃĐe par le navigateur. En mÊme temps, POST signifie que le navigateur a des donnÃĐes à transmettre au serveur.
- La ligne Content-Type: application/x-www-form-urlencoded indique quel type de donnÃĐes va envoyer le navigateur. Ce sont des donnÃĐes de formulaire (x-www-form) codÃĐes (urlencoded). Ce codage fait que certains caractÃĻres des donnÃĐes transmises sont transformÃĐes afin d'ÃĐviter au serveur des erreurs d'interprÃĐtation. Ainsi, l'espace est remplacÃĐ par +, la marque de fin de ligne par %OD%OA,âĶ De façon gÃĐnÃĐrale, tous les caractÃĻres contenus dans les donnÃĐes et susceptibles d'une interprÃĐtation erronÃĐe par le serveur (&, +, %âĶ) sont transformÃĐs en %XX oÃđ XX est leur code hexadÃĐcimal.
- La ligne Content-Length: 210 indique au serveur combien de caractÃĻres le client va lui envoyer une fois les entÊtes HTTP terminÃĐs, c.a.d. aprÃĻs la ligne vide signalant la fin des entÊtes.
- Les donnÃĐes (210 caractÃĻres)Â : R1=Oui&C1=un&C2=deux&txtSaisie=programmation+web&txtMdp=ceciestsecret&areaSaisie=les+bases+de+la%0D%0Aprogrammation+web&cmbValeurs=choix3&lst1=liste3&lst2=liste1&lst2=liste3&cmdRenvoyer=Envoyer&secret=uneValeur
On remarque que les donnÃĐes transmises par POST le sont au mÊme format que celle transmises par GET.
Y-a-t-il une mÃĐthode meilleure que l'autre ? Nous avons vu que si les valeurs d'un formulaire ÃĐtaient envoyÃĐes par le navigateur avec la mÃĐthode GET, le navigateur affichait dans son champ Adresse l'URL demandÃĐe sous la forme URL?param1=val1¶m2=val2&âĶ. On peut voir cela comme un avantage ou un inconvÃĐnient :
- un avantage si on veut permettre à l'utilisateur de placer cette URL paramÃĐtrÃĐe dans ses liens favoris
- un inconvÃĐnient si on ne souhaite pas que l'utilisateur ait accÃĻs à certaines informations du formulaire tels, par exemple, les champs cachÃĐs
Par la suite, nous utiliserons quasi exclusivement la mÃĐthode POST dans nos formulaires.
II-H-2-c. RÃĐcupÃĐration des valeurs d'un formulaire Web▲
Une page statique demandÃĐe par un client qui envoie de plus des paramÃĻtres par POST ou GET ne peut en aucune façon rÃĐcupÃĐrer ceux-ci. Seul un programme peut le faire et c'est lui qui se chargera alors de gÃĐnÃĐrer une rÃĐponse au client, une rÃĐponse qui sera dynamique et gÃĐnÃĐralement fonction des paramÃĻtres reçus. C'est le domaine de la programmation web, domaine que nous abordons plus en dÃĐtail dans le chapitre suivant avec la prÃĐsentation des technologies Java de programmation web : les servlets et les pages JSP.