


XI. Les threads d'exécution▲
XI-A. La classe Thread▲
Lorsqu'on lance une application, elle s'exécute dans un flux d'exécution appelé un thread. La classe .NET modélisant un thread est la classe System.Threading.Thread et a la définition suivante :
Constructeurs

Nous n'utiliserons dans les exemples à suivre que les constructeurs [1,3]. Le constructeur [1] admet comme paramètre une méthode ayant la signature [2], c.a.d. ayant un paramètre de type object et ne rendant pas de résultat. Le constructeur [3] admet comme paramètre une méthode ayant la signature [4], c.a.d. n'ayant pas de paramètre et ne rendant pas de résultat.
Propriétés
Quelques propriétés utiles :
- Thread CurrentThread : propriété statique qui donne une référence sur le thread dans lequel se trouve le code ayant demandé cette propriété
- string Name : le nom du thread
- bool IsAlive : indique si le thread est en cours d'exécution ou non.
Méthodes
Les méthodes les plus utilisées sont les suivantes :
- Start(), Start(object obj) : lance l'exécution asynchrone du thread, éventuellement en lui passant de l'information dans un type object.
- Abort(), Abort(object obj) : pour terminer de force un thread
- Join() : le thread T1 qui exécute T2.Join est bloqué jusqu'à ce que soit terminé le thread T2. Il existe des variantes pour terminer l'attente au bout d'un temps déterminé.
- Sleep(int n) : méthode statique - le thread exécutant la méthode est suspendu pendant n millisecondes. Il perd alors le processeur qui est donné à un autre thread.
Regardons une première application mettant en évidence l'existence d'un thread principal d'exécution, celui dans lequel s'exécute la fonction Main d'une classe :
- ligne 8 : on récupère une référence sur le thread dans lequel s'exécute la méthode [main]
- lignes 10-14 : on affiche et on modifie son nom
- lignes 17-22 : une boucle qui fait un affichage toutes les secondes
- ligne 21 : le thread dans lequel s'exécute la méthode [main] va être suspendu pendant 1 seconde
Les résultats écran sont les suivants :
- ligne 1 : le thread courant n'avait pas de nom
- ligne 2 : il en a un
- lignes 3-7 : l'affichage qui a lieu toutes les secondes
- ligne 8 : le programme est interrompu par Ctrl-C.
XI-B. Création de threads d'exécution▲
Il est possible d'avoir des applications où des morceaux de code s'exécutent de façon "simultanée" dans différents threads d'exécution. Lorsqu'on dit que des threads s'exécutent de façon simultanée, on commet souvent un abus de langage. Si la machine n'a qu'un processeur comme c'est encore souvent le cas, les threads se partagent ce processeur : ils en disposent, chacun leur tour, pendant un court instant (quelques millisecondes). C'est ce qui donne l'illusion du parallélisme d'exécution. La portion de temps accordée à un thread dépend de divers facteurs dont sa priorité qui a une valeur par défaut mais qui peut être fixée également par programmation. Lorsqu'un thread dispose du processeur, il l'utilise normalement pendant tout le temps qui lui a été accordé. Cependant, il peut le libérer avant terme :
- en se mettant en attente d'un événement (Wait, Join)
- en se mettant en sommeil pendant un temps déterminé (Sleep)
- Un thread T est tout d'abord créé par l'un des constructeurs présentés plus haut, par exemple :
où Start est une méthode ayant l'une des deux signatures suivantes :
- La création d'un thread ne lance pas celui-ci.
- L'exécution du thread T est lancé par T.Start() : la méthode Start passée au constructeur de T va alors être exécutée par le thread T. Le programme qui exécute l'instruction T.Start() n'attend pas la fin de la tâche T : il passe aussitôt à l'instruction qui suit. On a alors deux tâches qui s'exécutent en parallèle. Elles doivent souvent pouvoir communiquer entre elles pour savoir où en est le travail commun à réaliser. C'est le problème de synchronisation des threads.
- Une fois lancé, le thread T s'exécute de façon autonome. Il s'arrêtera lorsque la méthode Start qu'il exécute aura fini son travail.
- On peut forcer le thread T à se terminer :
- T.Abort() demande au thread T de se terminer.
- On peut aussi attendre la fin de son exécution par T.Join(). On a là une instruction bloquante : le programme qui l'exécute est bloqué jusqu'à ce que la tâche T ait terminé son travail. C'est un moyen de synchronisation.
Examinons le programme suivant :
- lignes 8-10 : on donne un nom au thread qui exécute la méthode [Main]
- lignes 13-21 : on crée 5 threads et on les exécute. Les références des threads sont mémorisées dans un tableau afin de pouvoir les récupérer ultérieurement. Chaque thread exécute la méthode Affiche des lignes 27-35.
- ligne 20 : le thread n° i est lancé. Cette opération est non bloquante. Le thread n° i va s'exécuter en parallèle du thread de la méthode [Main] qui l'a lancé.
- ligne 24 : le thread qui exécute la méthode [Main] se termine.
- lignes 27-35 : la méthode [Affiche] fait des affichages. Elle affiche le nom du thread qui l'exécute ainsi que les heures de début et fin d'exécution.
- ligne 31 : tout thread exécutant la méthode [Affiche] va s'arrêter pendant 1 seconde. Le processeur va alors être donné à un autre thread en attente de processeur. A la fin de la seconde d'arrêt, le thread arrêté va âtre candidat au processeur. Il l'aura lorsque son tour sera venu. Cela dépend de divers facteurs dont la priorité des autres threads en attente de processeur.
Les résultats sont les suivants :
Ces résultats sont très instructifs :
- on voit tout d'abord que le lancement de l'exécution d'un thread n'est pas bloquante. La méthode Main a lancé l'exécution de 5 threads en parallèle et a terminé son exécution avant eux. L'opération
lance l'exécution du thread tâches[i] mais ceci fait, l'exécution se poursuit immédiatement avec l'instruction qui suit sans attendre la fin d'exécution du thread.
- tous les threads créés doivent exécuter la méthode Affiche. L'ordre d'exécution est imprévisible. Même si dans l'exemple, l'ordre d'exécution semble suivre l'ordre des demandes d'exécution, on ne peut en conclure de généralités. Le système d'exploitation a ici 6 threads et un processeur. Il va distribuer le processeur à ces 6 threads selon des règles qui lui sont propres.
- on voit dans les résultats une conséquence de la méthode Sleep. Dans l'exemple, c'est le thread 0 qui exécute le premier la méthode Affiche. Le message de début d'exécution est affiché puis il exécute la méthode Sleep qui le suspend pendant 1 seconde. Il perd alors le processeur qui devient ainsi disponible pour un autre thread. L'exemple montre que c'est le thread 1 qui va l'obtenir. Le thread 1 va suivre le même parcours ainsi que les autres threads. Lorsque la seconde de sommeil du thread 0 va être terminée, son exécution peut reprendre. Le système lui donne le processeur et il peut terminer l'exécution de la méthode Affiche.
Modifions notre programme pour terminer la méthode Main par les instructions :
L'exécution du nouveau programme donne les résultats suivants :
- lignes 1-5 : les threads créés par la fonction Main commencent leur exécution et sont interrompus pendant 1 seconde
- ligne 6 : le thread [Main] récupère le processeur et exécute l'instruction :
Cette instruction arrête tous les threads de l'application et non simplement le thread Main.
Si la méthode Main veut attendre la fin d'exécution des threads qu'elle a créés, elle peut utiliser la méthode Join de la classe Thread :
- ligne 6 : le thread [Main] attend chacun des threads. Il est d'abord bloqué en attente du thread n° 1, puis du thread n° 2, etc… Au final lorsqu'il sort de la boucle des lignes 2-5, c'est ce que les 5 threads qu'il a lancés sont finis.
On obtient alors les résultats suivants :
- ligne 11 : le thread [Main] s'est terminé après les threads qu'il avait lancés.
XI-C. Intérêt des threads▲
Maintenant que nous avons mis en évidence l'existence d'un thread par défaut, celui qui exécute la méthode Main, et que nous savons comment en créer d'autres, arrêtons-nous sur l'intérêt pour nous des threads et sur les raisons pour lesquelles nous les présentons ici. Il y a un type d'applications qui se prêtent bien à l'utilisation des threads, ce sont les applications client-serveur de l'internet. Nous allons les présenter dans le chapitre qui suit. Dans une application client-serveur de l'internet, un serveur situé sur une machine S1 répond aux demandes de clients situés sur des machines distantes C1, C2…, Cn.
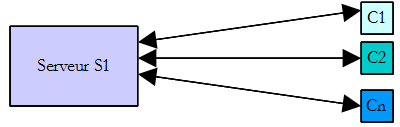
Nous utilisons tous les jours des applications de l'internet correspondant à ce schéma : services Web, messagerie électronique, consultation de forums, transfert de fichiers… Dans le schéma ci-dessus, le serveur S1 doit servir les clients Ci de façon simultanée. Si nous prenons l'exemple d'un serveur FTP (File Transfer Protocol) qui délivre des fichiers à ses clients, nous savons qu'un transfert de fichier peut prendre parfois plusieurs minutes. Il est bien sûr hors de question qu'un client monopolise tout seul le serveur pendant une telle durée. Ce qui est fait habituellement, c'est que le serveur crée autant de threads d'exécution qu'il y a de clients. Chaque thread est alors chargé de s'occuper d'un client particulier. Le processeur étant partagé cycliquement entre tous les threads actifs de la machine, le serveur passe alors un peu de temps avec chaque client assurant ainsi la simultanéité du service.
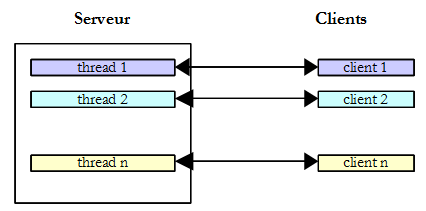
Dans la pratique, le serveur utilise un pool de threads avec un nombre limité de threads, 50 par exemple. Le 51 ième client est alors prié d'attendre.
XI-D. Echange d'informations entre threads▲
Dans les exemples précédents, un thread était initialisé de la façon suivante :
où Run était une méthode ayant la signature suivante :
Il est également possible d'utiliser la signature suivante :
Cela permet de transmettre de l'information au thread lancé. Ainsi
va lancer le thread t qui va alors exécuter la méthode Run qui lui a été associée par construction, en lui passant le paramètre effectif obj1. Voici un exemple :
- lignes 45-50 : l'information de type [Data] passée aux threads :
- Début : heure du début de l'exécution du thread - fixée par le thread lanceur
- Durée : durée en secondes du Sleep exécuté par le thread lancé - fixée par le thread lanceur
- Fin : heure du début de l'exécution du thread - fixée par le thread lancé
Il y a là un échange d'informations entre le thread lanceur et le thread lancé. - lignes 35-43 : la méthode Sleep exécutée par les threads a la signature void Sleep(object obj). Le paramètre effectif obj sera du type [Data] défini ligne 45.
- lignes 15-22 : création de 5 threads
- ligne 17 : chaque thread est associé à la méthode Sleep de la ligne 35
- ligne 21 : un objet de type [Data] est passé à la méthode Start qui lance le thread. Dans cet objet on a noté l'heure de début de l'exécution du thread ainsi que la durée en secondes pendant laquelle il doit dormir. Cet objet est mémorisé dans le tableau de la ligne 14.
- lignes 24-30 : le thread [Main] attend la fin de tous les threads qu'il a lancés.
- lignes 28-29 : le thread [Main] récupère l'objet data[i] du thread n° i et en affiche le contenu.
- lignes 35-42 : la méthode Sleep exécutée par les threads
- ligne 37 : on récupère le paramètre de type [Data]
- ligne 39 : le champ Durée du paramètre est utilisé pour fixer la durée du Sleep
- ligne 41 : le champ Fin du paramètre est initialisé
Les résultats de l'exécution sont les suivants :
Cet exemple montre que deux threads peuvent s'échanger de l'information :
- le thread lanceur peut contrôler l'exécution du thread lancé en lui donnant des informations
- le thread lancé peut rendre des résultats au thread lanceur.
Pour que le thread lancé sache à quel moment les résultats qu'il attend sont disponibles, il faut qu'il soit averti de la fin du thread lancé. Ici, il a attendu qu'il se termine en utilisant la méthode Join. Il y a d'autres façons de faire la même chose. Nous les verrons ultérieurement.
XI-E. Accès concurrents à des ressources partagées▲
XI-E-1. Accès concurrents non synchronisés▲
Dans le paragraphe sur l'échange d'informations entre threads, l'information échangée ne l'était que par deux threads et à des moments bien précis. On avait là un classique passage de paramètres. Il existe d'autres cas où une information est partagée par plusieurs threads qui peuvent vouloir la lire ou la mettre à jour au même moment. Se pose alors le problème de l'intégrité de cette information. Supposons que l'information partagée soit une structure S avec diverses informations I1, I2… In.
- un thread T1 commence à mettre à jour la structure S : il modifie le champ I1 et est interrompu avant d'avoir terminé la mise à jour complète de la structure S
- un thread T2 qui récupère le processeur lit alors la structure S pour prendre des décisions. Il lit une structure dans un état instable : certains champs sont à jour, d'autres pas.
On appelle cette situation, l'accès à une ressource partagée, ici la structure S, et elle est souvent assez délicate à gérer. Prenons l'exemple suivant pour illustrer les problèmes qui peuvent surgir :
- une application va générer n threads, n étant passé en paramètre
- la ressource partagée est un compteur qui devra être incrémenté par chaque thread généré
- à la fin de l'application, la valeur du compteur est affichée. On devrait donc trouver n.
Le programme est le suivant :
Nous ne nous attarderons pas sur la partie génération de threads déjà étudiée. Intéressons-nous plutôt à la méthode Incrémente, de la ligne 59 utilisée par chaque thread pour incrémenter le compteur statique cptrThreads de la ligne 8.
- ligne 62 : le compteur est lu
- ligne 66 : le thread s'arrête 1 s. Il perd donc le processeur
- ligne 68 : le compteur est incrémenté
L'étape 2 n'est là que pour forcer le thread à perdre le processeur. Celui-ci va être donné à un autre thread. Dans la pratique, rien n'assure qu'un thread ne sera pas interrompu entre le moment où il va lire le compteur et le moment où il va l'incrémenter. Même si on écrit cptrThreads++, donnant ainsi l'illusion d'une instruction unique, le risque existe de perdre le processeur entre le moment où on lit la valeur du compteur et celui on écrit sa valeur incrémentée de 1. En effet, l'opération de haut niveau cptrThreads++ va faire l'objet de plusieurs instructions élémentaires au niveau du processeur. L'étape 2 de sommeil d'une seconde n'est donc là que pour systématiser ce risque.
Les résultats obtenus avec 5 threads sont les suivants :
A la lecture de ces résultats, on voit bien ce qui se passe :
- ligne 1 : un premier thread lit le compteur. Il trouve 0. Il s'arrête 1 s donc perd le processeur
- ligne 2 : un second thread prend alors le processeur et lit lui aussi la valeur du compteur. Elle est toujours à 0 puisque le thread précédent ne l'a pas encore incrémentée. Il s'arrête lui aussi 1 s et perd à son tour le processeur.
- lignes 1-5 : en 1 s, les 5 threads ont le temps de passer tous et de lire tous la valeur 0.
- lignes 6-10 : lorsqu'ils vont se réveiller les uns après les autres, ils vont incrémenter la valeur 0 qu'ils ont lue et écrire la valeur 1 dans le compteur, ce que confirme le programme principal (Main) en ligne 11.
D'où vient le problème ? Le second thread a lu une mauvaise valeur du fait que le premier avait été interrompu avant d'avoir terminé son travail qui était de mettre à jour le compteur dans la fenêtre. Cela nous amène à la notion de ressource critique et de section critique d'un programme:
- une ressource critique est une ressource qui ne peut être détenue que par un thread à la fois. Ici la ressource critique est le compteur.
- une section critique d'un programme est une séquence d'instructions dans le flux d'exécution d'un thread au cours de laquelle il accède à une ressource critique. On doit assurer qu'au cours de cette section critique, il est le seul à avoir accès à la ressource.
Dans notre exemple, la section critique est le code situé entre la lecture du compteur et l'écriture de sa nouvelle valeur :
Pour exécuter ce code, un thread doit être assuré d'être tout seul. Il peut être interrompu mais pendant cette interruption, un autre thread ne doit pas pouvoir exécuter ce même code. La plate-forme .NET offre divers outils pour assurer l'entrée unitaire dans les sections critiques de code. Nous en voyons quelques-uns maintenant.
XI-E-2. La clause lock▲
La clause lock permet de délimiter une section critique de la façon suivante :
obj doit être une référence d'objet visible par tous les threads exécutant la section critique. La clause lock assure qu'un seul thread à la fois exécutera la section critique. L'exemple précédent est réécrit comme suit :
- ligne 9 : synchro est l'objet qui va permettre la synchronisation de tous les threads.
- lignes 16-23 : la méthode [Main] attend les threads dans l'ordre inverse de leur création.
- lignes 29-40 : la section critique de la méthode Incrémente a été encadrée par la clause lock.
Les résultats obtenus avec 3 threads sont les suivants :
- le thread 0 entre le 1er dans la section critique : lignes 1, 2, 6, 8
- les deux autres threads vont être bloqués tant que le thread 0 ne sera pas sorti de la section critique : lignes 3 et 4
- le thread 1 passe ensuite : lignes 7, 9, 10
- le thread 2 passe ensuite : lignes 11, 12, 13
- ligne 14 : le thread Main qui attendait la fin du thread 2 est prévenu
- ligne 15 : le thread Main attend maintenant la fin du thread 1. Celui-ci est déjà terminé. Le thread Main en est prévenu immédiatement, ligne 16.
- lignes 17-18 : le même processus se passe avec le thread 0
- ligne 19 : le nombre de threads est correct
XI-E-3. La classe Mutex▲
La classe System.Threading.Mutex permet elle aussi de délimiter des sections critiques. Elle diffère de la clause lock en terme de visibilité :
- la clause lock permet de synchroniser des threads d'une même application
- la classe Mutex permet de synchroniser des threads de différentes applications.
Nous utiliserons le constructeur et les méthodes suivants :
| public Mutex() | crée un Mutex M |
| public bool WaitOne() | Le thread T1 qui exécute l'opération M.WaitOne() demande la propriété de l'objet de synchronisation M. Si le Mutex M n'est détenu par aucun thread (le cas au départ), il est "donné" au thread T1 qui l'a demandé. Si un peu plus tard, un thread T2 fait la même opération, il sera bloqué. En effet, un Mutex ne peut appartenir qu'à un thread. Il sera débloqué lorsque le thread T1 libèrera le Mutex M qu'il détient. Plusieurs threads peuvent ainsi être bloqués en attente du Mutex M. |
| public void ReleaseMutex() | Le thread T1 qui effectue l'opération M.ReleaseMutex() abandonne la propriété du Mutex M. Lorsque le thread T1 perdra le processeur, le système pourra donner celui-ci à l'un des threads en attente du Mutex M. Un seul l'obtiendra à son tour, les autres en attente de M restant bloqués |
Un Mutex M gère l'accès à une ressource partagée R. Un thread demande la ressource R par M.WaitOne() et la rend par M.ReleaseMutex(). Une section critique de code qui ne doit être exécutée que par un seul thread à la fois est une ressource partagée. La synchronisation d'exécution de la section critique peut se faire ainsi :
où M est un objet Mutex. Il ne faut pas oublier de libérer un Mutex devenu inutile afin qu'un autre thread puisse entrer dans la section critique, sinon les threads en attente du Mutex jamais libéré n'auront jamais accès au processeur.
Si nous mettons en pratique sur l'exemple précédent ce que nous venons de voir, notre application devient la suivante :
- ligne 9 : l'objet de synchronisation des threads est désormais un Mutex.
- ligne 18 : début de la section critique - un seul thread doit y entrer. On se bloque jusqu'à ce que le Mutex synchro soit libre.
- ligne 33 : parce qu'un Mutex doit toujours être libéré, exception ou pas, on gère la section critique avec un try / finally afin de libérer le Mutex dans le finally.
- ligne 23 : le Mutex est libéré une fois la section critique passée.
Les résultats obtenus sont les mêmes que précédemment.
XI-E-4. La classe AutoResetEvent▲
Un objet AutoResetEvent est une barrière ne laissant passer qu'un thread à la fois, comme les deux outils précédents lock et Mutex. On construit un objet AutoResetEvent de la façon suivante :
Le booléen état indique l'état fermé (false) ou ouvert (true) de la barrière. Un thread voulant passer la barrière l'indiquera de la façon suivante :
- si la barrière est ouverte, le thread passe et la barrière est refermée derrière lui. Si plusieurs threads attendaient, on est assuré qu'un seul passera.
- si la barrière est fermée, le thread est bloqué. Un autre thread l'ouvrira lorsque le moment sera venu. Ce moment est entièrement dépendant du problème traité. La barrière sera ouverte par l'opération :
Il peut arriver qu'un thread veuille fermer une barrière. Il pourra le faire par :
Si dans l'exemple précédent, on remplace l'objet Mutex par un objet de type AutoResetEvent, le code devient le suivant :
- ligne 9 : la barrière est créée fermée. Elle sera ouverte par le thread Main ligne 16.
- ligne 27 : le thread chargé d'incrémenter le compteur de threads demande l'autorisation d'entrer dans la section critique. Les différents threads vont s'accumuler devant la barrière fermée. Lorque le thread Main va l'ouvrir, l'un des threads en attente va passer.
- ligne 33 : lorsqu'il a terminé son travail, il rouvre la barrière permettant à un autre thread d'entrer.
On obtient des résultats analogues aux précédents.
XI-E-5. La classe Interlocked▲
La classe Interlocked permet de rendre atomique un groupe d'opérations. Dans un groupe d'opérations atomique, soit toutes les opérations sont exécutées par le thread qui exécute le groupe soit aucune. On ne reste pas dans un état ou certaines ont été exécutées et d'autres pas. Les objets de synchronisation lock, Mutex, AutoResetEvent ont toutes pour but de rendre atomique un groupe d'opérations. Ce résultat est obtenu au prix du blocage de threads. La classe Interlocked permet, pour des opérations simples mais assez fréquentes, d'éviter le blocage de threads. La classe Interlocked offre les méthodes statiques suivantes :

La méthode Increment a la signature suivante :
Elle permet d'incrémenter de 1 le paramètre location. L'opération est garantie atomique.
Notre programme de comptage de threads peut alors être le suivant :
- ligne 17 : le compteur de threads est incrémenté de façon atomique.
XI-F. Accès concurrents à des ressources partagées multiples▲
XI-F-1. Un exemple▲
Dans nos exemples précédents, une unique ressource était partagée par les différents threads. La situation peut se compliquer s'il y en a plusieurs et qu'elles sont dépendantes les unes des autres. Une situation d'interblocage peut notamment survenir. Cette situation appelée également deadlock est celle dans laquelle deux threads s'attendent mutuellement. Considérons les actions suivantes qui se suivent dans le temps :
- un thread T1 obtient la propriété d'un Mutex M1 pour avoir accès à une ressource partagée R1
- un thread T2 obtient la propriété d'un Mutex M2 pour avoir accès à une ressource partagée R2
- le thread T1 demande le Mutex M2. Il est bloqué.
- le thread T2 demande le Mutex M1. Il est bloqué.
Ici, les threads T1 et T2 s'attendent mutuellement. Ce cas apparaît lorsque des threads ont besoin de deux ressources partagées, la ressource R1 contrôlée par le Mutex M1 et la ressource R2 contrôlée par le Mutex M2. Une solution possible est de demander les deux ressources en même temps à l'aide d'un Mutex unique M. Mais ce n'est pas toujours possible si par exemple cela entraîne une mobilisation longue d'une ressource coûteuse. Une autre solution est qu'un thread ayant M1 et ne pouvant obtenir M2, relâche alors M1 pour éviter l'interblocage.
- On a un tableau dans lequel des threads viennent déposer des données (les écrivains) et d'autres viennent les lire (les lecteurs).
- Les écrivains sont égaux entre-eux mais exclusifs : un seul écrivain à la fois peut déposer ses données dans le tableau.
- Les lecteurs sont égaux entre-eux mais exclusifs : un seul lecteur à la fois peut lire les données déposées dans le tableau.
- Un lecteur ne peut lire les données du tableau que lorsqu'un écrivain en a déposé dedans et un écrivain ne peut déposer de nouvelles données dans le tableau que lorsque celles qui y sont ont été lues par un lecteur.
On peut distinguer deux ressources partagées :
-
- le tableau en écriture : un seul écrivain à la fois doit y avoir accès.
- le tableau en lecture : un seul lecteur à la fois doit y avoir accès.
et un ordre d'utilisation de ces ressources :
- un lecteur doit toujours passer après un écrivain.
- un écrivain doit toujours passer après un lecteur, sauf la 1re fois.
On peut contrôler l'accès à ces deux ressources avec deux barrières de type AutoResetEvent :
- la barrière peutEcrire contrôlera l'accès des écrivains au tableau.
- la barrière peutLire contrôlera l'accès des lecteurs au tableau.
- la barrière peutEcrire sera créée initialement ouverte laissant passer ainsi un 1er écrivain et bloquant tous les autres.
- la barrière peutLire sera créée initialement fermée bloquant tous les lecteurs.
- lorsqu'un écrivain aura terminé son travail, il ouvrira la barrière peutLire pour laisser entrer un lecteur.
- lorsqu'un lecteur aura terminé son travail, il ouvrira la barrière peutEcrire pour laisser entrer un écrivain.
Le programme illustrant cette synchronisation par événements est le suivant :
- ligne 11 : le tableau data est la ressource partagée entre les threads lecteurs et écrivains. Elle est partagée en lecture par les threads lecteurs, en écriture par les threads écrivains.
- ligne 13 : l'objet peutLire sert à avertir les threads lecteurs qu'ils peuvent lire le tableau data. Il est mis à vrai par le thread écrivain ayant rempli le tableau data. Il est initialisé à false, ligne 23. Il faut qu'un thread écrivain remplisse d'abord le tableau avant de passer l'événement peutLire à vrai.
- ligne 14 : l'objet peutEcrire sert à avertir les threads écrivains qu'ils peuvent écrire dans le tableau data. Il est mis à vrai par le thread lecteur ayant exploité la totalité du tableau data. Il est initialisé à true, ligne 24. En effet, le tableau data est libre en écriture.
- lignes 27-34 : création et lancement des threads lecteurs
- lignes 37-44 : création et lancement des threads écrivains
La méthode Lire exécutée par les threads lecteurs est la suivante :
- ligne 5 : on attend qu'un thread écrivain signale que le tableau a été rempli. Lorsque ce signal sera reçu, un seul des threads lecteurs en attente de ce signal pourra passer.
- lignes 7-12 : exploitation du tableau data avec un Sleep au milieu pour forcer le thread à perdre le processeur.
- ligne 14 : indique aux threads écrivains que le tableau a été lu et qu'il peut être rempli de nouveau.
La méthode Ecrire exécutée par les threads écrivains est la suivante :
- ligne 5 : on attend qu'un thread lecteur signale que le tableau a été lu. Lorsque ce signal sera reçu, un seul des threads écrivains en attente de ce signal pourra passer.
- lignes 7-13 : exploitation du tableau data avec un Sleep au milieu pour forcer le thread à perdre le processeur.
- ligne 15 : indique aux threads lecteurs que le tableau a été rempli et qu'il peut être lu de nouveau.
L'exécution donne les résultats suivants :
On peut remarquer les points suivants :
- on a bien 1 seul lecteur à la fois, bien que celui-ci perde le processeur dans la section critique Lire
- on a bien 1 seul écrivain à la fois, bien que celui-ci perde le processeur dans la section critique Ecrire
- un lecteur ne lit que lorsqu'il y a quelque chose à lire dans le tableau
- un écrivain n'écrit que lorsque le tableau a été entièrement lu
XI-F-2. La classe Monitor▲
Dans l'exemple précédent :
- il y a deux ressources partagées à gérer
- pour une ressource donnée, les threads sont égaux.
Lorsque les threads écrivains sont bloqués sur l'instruction peutEcrire.WaitOne, l'un d'entre-eux, n'importe lequel, est débloqué par l'opération peutEcrire.Set. Si l'opération précédente doit ouvrir la barrière à un écrivain en particulier, les choses deviennent plus compliquées.
On peut considérer l'analogie avec un établissement accueillant du public à des guichets où chaque guichet est spécialisé. Lorsque le client arrive, il prend un ticket au distributeur de tickets pour le guichet X puis va s'asseoir. Chaque ticket est numéroté et les clients sont appelés par leur numéro via un haut-parleur. Pendant son attente, le client fait ce qu'il veut. Il peut lire ou somnoler. Il est réveillé à chaque fois par le haut-parleur qui annonce que le n° Y est appelé au guichet X. S'il s'agit de lui, le client se lève et accède au guichet X, sinon il continue ce qu'il faisait.
On peut ici fonctionner de façon analogue. Prenons l'exemple des écrivains :
| plusieurs écrivains attendent pour un même guichet | leurs threads sont bloqués |
| le guichet se libère et le n° de l'écrivain suivant est appelé | le thread qui utilisait le tableau en lecture indique aux écrivains que le tableau est disponible. Lui ou un autre thread a fixé le thread écrivain qui doit passer la barrière. |
| chaque écrivain regarde son n° et seul celui qui a le n° appelé va au guichet. Les autres se remettent en attente. | chaque thread vérifie s'il est l'élu. Si oui, il passe la barrière. Si non, il se remet en attente. |
La classe Monitor permet de mettre en œuvre ce scénario.
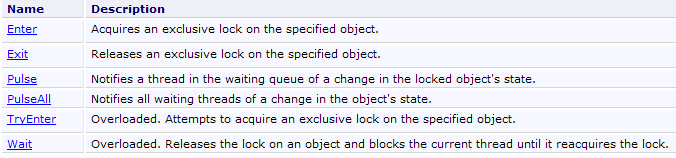
Nous décrivons maintenant une construction standard (pattern), proposée dans le chapitre Threading du livre C# 3.0 référencé dans l'introduction de ce document, capable de résoudre les problèmes de barrière avec condition d'entrée.
- Tout d'abord, les threads qui se partagent une ressource (le guichet…) y accèdent via un objet que nous appellerons un jeton. Pour ouvrir la barrière qui mène au guichet, il faut avoir le jeton pour l'ouvrir et il n'y a qu'un seul jeton. Les threads doivent donc se passer le jeton entre-eux.
- Pour aller au guichet, les threads demandent tout d'abord le jeton :
Si le jeton est libre, il est donné au thread ayant exécuté l'opération précédente, sinon le thread est mis en attente du jeton.
- Si l'accès au guichet se fait de façon non ordonnée, c.a.d. dans le cas où la personne qui entre n'importe pas, l'opération précédente est suffisante. Le thread ayant le jeton va au guichet. Si l'accès se fait de façon ordonnée, le thread qui a le jeton vérifie qu'il remplit la condition pour aller au guichet :
Si le thread n'est pas celui qui est attendu au guichet, il laisse son tour en redonnant le jeton. Il passe dans un état bloqué. Il sera réveillé dès que le jeton redeviendra disponible pour lui. Il vérifiera alors de nouveau s'il vérifie la condition pour aller au guichet. L'opération Monitor.Wait(jeton) qui relâche le jeton ne peut être faite que si le thread est propriétaire du jeton. Si ce n'est pas le cas, une exception est lancée.
- Le thread qui vérifie la condition pour aller au guichet y va :
Avant de quitter le guichet, le thread doit rendre son jeton, sinon les threads bloqués en attente de celui-ci le resteront indéfiniment. Il y a deux situations différentes :
- la première situation est celle où le thread ayant le jeton est également celui qui signale aux threads en attente du jeton que celui-ci est libre. Il le fera de la façon suivante :
Ligne 6, il réveille les threads en attente du jeton. Ce réveil signifie qu'ils deviennent éligibles pour recevoir le jeton. Cela ne veut pas dire qu'ils le reçoivent immédiatement. Ligne 8, le jeton est libéré. Tous les threads éligibles vont recevoir tour à tour le jeton, de façon indéterministe. Cela va leur donner l'occasion de vérifier de nouveau s'ils vérifient la condition d'accès. Le thread ayant libéré le jeton a modifié cette condition ligne 4 afin de permettre à un nouveau thread d'entrer. Le premier qui la vérifie garde le jeton et va au guichet à son tour.
- la seconde situation est celle où le thread ayant le jeton n'est pas celui qui doit signaler aux threads en attente du jeton que celui-ci est libre. Il doit néanmoins le libérer parce que le thread chargé d'envoyer ce signal doit être détenteur du jeton. Il le fera par l'opération :
Le jeton est désormais disponible, mais les threads qui l'attendent (ils ont fait une opération Wait(jeton)) n'en sont pas avertis. Cette tâche est confiée à un autre thread qui à un moment donné exécutera un code similaire au suivant :
Au final, la construction standard proposée dans le chapitre Threading du livre C# 3.0 est la suivante :
- définir le jeton d'accès au guichet :
- demander l'accès au guichet :
est équivalent à
On notera que dans ce schéma le jeton est relâché immédiatement, dès que la barrière est passée. Un autre thread peut alors tester la condition d'accès. La construction précédente laisse donc entrer tous les threads vérifiant la condition d'accès. Si ce n'est pas ce qui est désiré, on pourra écrire :
où le jeton n'est relâché qu'après le passage au guichet.
- modifier la condition d'accès au guichet et en avertir les autres threads
Ci-dessus, la condition d'accès ne peut être modifiée que par le thread ayant le jeton. On pourra aussi écrire :
si le thread a déjà le jeton.
Muni de ces informations, nous pouvons réécrire l'application lecteurs / écrivains en fixant un ordre des lecteurs et des écrivains pour l'accès à leurs guichets respectifs. Le code est le suivant :
L'accès au guichet de lecture est conditionné par les éléments suivants :
- ligne 13 : le jeton peutLire
- ligne 15 : le booléen lectureAutorisée
- ligne 17 : le tableau ordonné des lecteurs. Les lecteurs vont au guichet de lecture dans l'ordre de ce tableau qui contient leurs noms.
- ligne 19 : lecteurSuivant indique le n° du prochain lecteur autorisé à aller au guichet.
L'accès au guichet d'écriture est conditionné par les éléments suivants :
- ligne 14 : le jeton peutEcrire
- ligne 16 : le booléen écritureAutorisée
- ligne 18 : le tableau ordonné des écrivains. Les écrivains vont au guichet d'écriture dans l'ordre de ce tableau qui contient leurs noms.
- ligne 20 : écrivainSuivant indique le n° du prochain écrivain autorisé à aller au guichet.
Les autres éléments du code sont les suivants :
- lignes 29-36 : création et lancement des threads lecteurs. Ils seront tous bloqués car la lecture n'est pas autorisée (ligne 15).
- lignes 39-43 : leur ordre de passage au guichet se fera dans l'ordre inverse de leur création.
- lignes 46-53 : création et lancement des threads érivains. Ils seront tous bloqués car l'écriture n'est pas autorisée (ligne 16).
- lignes 56-60 : leur ordre de passage au guichet se fera dans l'ordre de leur création.
- ligne 64 : on autorise l'écriture
- ligne 65 : on avertit les écrivains que quelque chose a changé.
La méthode Lire est la suivante :
- l'ensemble de l'accès au guichet est contrôlé par le lock des lignes 5-27. Le lecteur qui récupère le jeton le garde pendant tout son passage au guichet
- lignes 6-8 : un lecteur ayant acquis le jeton ligne 5 le relâche si la lecture n'est pas autorisée ou si ce n'est pas à son tour de passer.
- lignes 10-15 : passage au guichet (exploitation du tableau)
- lignes 17-18 : le thread change les conditions d'accès au guichet de lecture. On notera qu'il a toujours le jeton de lecture et que ces modifications ne peuvent pas encore permettre à un lecteur de passer.
- lignes 20-23 : le thread change les conditions d'accès au guichet d'écriture et prévient tous les écrivains en attente que quelque chose a changé.
- ligne 27 : le lock se termine, le jeton peutLire est relâché. Un thread de lecture pourrait alors l'acquérir ligne 5 mais il ne passerait pas la condition d'accès puisque le booléen lectureAutorisée est à faux. Par ailleurs, tous les threads qui sont en attente du jeton peutLire le restent car l'opération PulseAll(peutLire) n'a pas encore eu lieu.
La méthode Ecrire est la suivante :
- l'ensemble de l'accès au guichet d'écriture est contrôlé par le lock des lignes 5-27. L'écrivain qui récupère le jeton le garde pendant tout son passage au guichet
- lignes 6-8 : un écrivain ayant acquis le jeton ligne 5 le relâche si l'écriture n'est pas autorisée ou si ce n'est pas à son tour de passer.
- lignes 10-16 : passage au guichet (exploitation du tableau)
- lignes 18-19 : le thread change les conditions d'accès au guichet d'écriture. On notera qu'il a toujours le jeton d'écriture et que ces modifications ne peuvent pas encore permettre à un écrivain de passer.
- lignes 21-24 : le thread change les conditions d'accès au guichet de lecture et prévient tous les lecteurs en attente que quelque chose a changé.
- ligne 27 : le lock se termine, le jeton peutEcrire est relâché. Un thread d'écriture pourrait alors l'acquérir ligne 5 mais il ne passerait pas la condition d'accès puisque le booléen écritureAutorisée est à faux. Par ailleurs, tous les threads qui sont en attente du jeton peutEcrire le restent dans l'attente d'une nouvelle opération PulseAll(peutEcrire).
Un exemple d'exécution est le suivant :
XI-G. Les pools de threads▲
Jusqu'à maintenant, pour gérer des threads :
- nous les avons créés par Thread T=new Thread(…)
- puis exécutés par T.Start()
Nous avons vu au chapitre "Bases de données" qu'avec certains SGBD il était possible d'avoir des pools de connexions ouvertes :
- n connexions sont ouvertes au démarrage du pool
- lorsqu'un thread demande une connexion, on lui donne l'une des connexions ouvertes du pool
- lorsque le thread ferme la connexion, elle n'est pas fermée mais rendue au pool
L'usage d'un pool de connexions est transparent au niveau du code. L'intérêt réside dans l'amélioration des performances : l'ouverture d'une connexion coûte cher. Ici 10 connexions ouvertes peuvent servir des centaines de demandes.
Un système analogue existe pour les threads :
- min threads sont créés au démarrage du pool. La valeur de min est fixée avec la méthode ThreadPool.SetMinThreads(min1,min2). Un pool de threads peut être utilisé pour exécuter des tâches bloquantes ou non bloquantes dites asynchrones. Le premier paramètre min1 fixe le nombre de threads bloquants, le second min2 le nombre de threads asynchrones. Les valeurs actuelles de ces deux valeurs peuvent être obtenues par ThreadPool.GetMinThreads(out min1,out min2).
- si ce nombre n'est pas suffisant, le pool va créer d'autres threads pour répondre aux demande jusqu'à la limite de max threads. La valeur de max est fixée avec la méthode ThreadPool.SetMaxThreads(max1,max2). Les deux paramètres ont la même signification que dans la méthode SetMinThreads. Les valeurs actuelles de ces deux valeurs peuvent être obtenues par ThreadPool.GetMaxThreads(out max1,out max2). Lorsque les max1 threads auront été atteints, les demandes de threads pour tâches bloquantes seront mises en attente d'un thread libre dans le pool.
Un pool de threads offre divers avantages :
- comme pour le pool de connexions, on économise sur le temps de création des threads : 10 threads peuvent servir des centaines de demandes.
- on sécurise l'application : en fixant un nombre maximum de threads, on évite l'asphyxie de l'application par des demandes trop nombreuses. Celles-ci seront mises en file d'attente.
Pour donner une tâche à un thread du pool, on utilise l'une des deux méthodes :
- ThreadPool.QueueWorkItem(WaitCallBack)
- ThreadPool.QueueWorkItem(WaitCallBack,object)
où WaitCallBack est toute méthode ayant la signature void WaitCallBack(object). La méthode 1 demande à un thread d'exécuter la méthode WaitCallBack sans lui passer de paramètre. La méthode 2 fait la même chose mais en passant un paramètre de type object à la méthode WaitCallBack.
Voici un programme illustrant ces concepts :
- ligne 15-17 : on demande et affiche le nombre minimal actuel des deux types de threads du pool de threads
- ligne 18 : on change le nombre minimal de threads pour tâches bloquantes : 2
- lignes 19-21 : on affiches les nouveaux minima
- lignes 22-28 : on fait de même pour fixer le nombre maximal de threads pour tâches bloquantes : 5
- lignes 30-33 : on fait exécuter 7 tâches dans un pool de 5 threads. 5 tâches devraient obtenir 1 thread, les 2 premières rapidement puisque 2 threads sont toujours présents, les 3 autres avec un délai d'attente de 0.5 seconde. 2 tâches devraient attendre qu'un thread se libère.
- ligne 32 : les tâches exécutent la méthode Sleep des lignes 40-54 en lui passant un paramètre de type Data2 défini lignes 56-62.
- ligne 40 : la méthode Sleep exécutée par les tâches
- ligne 42 : on récupère le paramètre passé à la méthode Sleep.
- ligne 43 : la tâche s'identifie sur la console
- lignes 45-47 : on affiche le nombre de threads actuellement disponibles. On veut voir comment il évolue.
- ligne 49 : la tâche s'arrête quelques secondes (tâche bloquante).
- ligne 52 : lorsqu'elle se réveille, on fait afficher quelques informations sur son compte.
Les résultats obtenus sont les suivants.
Pour les nombres min et max de threads dans le pool :
Pour l'exécution des 7 threads :
- lignes 1-6 : les 3 premières tâches sont exécutées tour à tour. Elles trouvent imédiatement 1 thread disponible (MinThreads=3) puis se mette en sommeil.
- lignes 7-9 : pour les tâches 3 et 4, c'est un peu plus long. Pour chacun d'eux il n'y avait pas de thread libre. Il a fallu en créer un. Ce mécanisme est possible jusqu'à 5 (MaxThreads=5).
- ligne 10 : il n'y a plus de threads disponibles : les tâches 5 et 6 vont devoir attendre.
- lignes 11-12 : la tâche 0 se termine. La tâche 5 prend son thread.
- lignes 13-14 : la tâche 1 se termine. La tâche 6 prend son thread.
- lignes 17-21 : les tâches se terminent les unes après les autres.
XI-H. La classe BackgroundWorker▲
XI-H-1. Exemple 1▲
La classe BackgroundWorker appartient à l'espace de noms [System.ComponentModel]. Elle s'utilise comme un thread mais présente des particularités qui peuvent la rendre, dans certains cas, plus intéressante que la classe [Thread] :
- elle émet les événements suivants :
- DoWork : un thread a demandé l'exécution du BackgroundWorker
- ProgressChanged : l'objet BackgroundWorker a exécuté la méthode ReportProgress. Celle-ci sert à donner un pourcentage d'exécution.
- RunWorkerCompleted : l'objet BackgroundWorker a terminé son travail. Il a pu le terminer normalement ou sur annulation ou exception.
Ces événements rendent le BackgroundWorker utile dans les interfaces graphiques : une tâche longue sera confiée à un BackgroundWorker qui pourra rendre compte de son avancement avec l'événement ProgressChanged et sa fin avec l'événement RunWorkerCompleted. Le travail à effectuer par le BackgroundWorker sera gfait par une méthode qui aura été associée à l'événement DoWork.
- il est possible de demander son annulation. Dans une interface graphique, une tâche longue pourra ainsi être annulée par l'utilisateur.
- les objets BackgroundWorker appartiennent à un pool et sont recyclés selon les besoins. Une application qui a besoin d'un objet BackgroundWorker l'obtiendra auprès du pool qui lui donnera un thread déjà existant mais inutilisé. Le fait de recycler ainsi les threads plutôt que de créer à chaque fois un thread neuf, améliore les performances.
Nous utilisons cet outil sur l'application précédente dans le cas où l'accès au guichet est non contrôlé :
Nous ne détaillons que les changements :
- la classe Thread est remplacée par la classe MyBackgroundWorker des lignes 79-82. La classe BackgroundWorker a été dérivée afin de donner un numéro au thread. On aurait pu procéder différemment en passant un objet à la méthode RunWorkerAsync des lignes 43 et 54, objet contenant le n° du thread.
- ligne 58 : la méthode Main se termine après que tous les threads lecteurs ont fait leur travail. Pour cela, ligne 12, le compteur nbLecteursTerminés compte le nombre de threads lecteurs ayant terminé leur travail. Ce compteur est incrémenté par la méthode EndLecteur des lignes 63-65 qui est exécutée à chaque fois qu'un thread lecteur se termine. C'est cette procédure qui contrôle l'événement AutoResetEvent finLecteurs de la ligne 18 sur lequel se synchronise, ligne 59, la méthode Main.
- ligne 16 : parce que plusieurs threads lecteurs peuvent vouloir incrémenter en même temps le compteur nbLecteursTerminés, un accès exclusif à celui-ci est assuré par l'objet de synchronisation appli. Ce cas est improbable mais théoriquement possible.
- lignes 35-44 : création des threads lecteurs
- ligne 38 : création du thread de type MyBackgroundWorker
- ligne 39 : on lui donne un N°
- ligne 40 : on lui assigne la méthode Lire à exécuter
- ligne 41 : la méthode EndLecteur sera exécutée après la fin du thread
- ligne 43 : le thread est lancé
- lignes 47-55 : création des threads écrivains
- ligne 50 : création du thread de type MyBackgroundWorker
- ligne 51 : on lui donne un N°
- ligne 52 : on lui assigne la méthode Ecrire à exécuter
- ligne 54 : le thread est lancé
Les méthodes Lire et Ecrire restent inchangées. La méthode EndLecteur est exécutée à la fin de chaque thread lecteur. Son code est le suivant :
Le rôle de la méthode EndLecteur est d'avertir la méthode Main que tous les lecteurs ont fait leur travail.
- ligne 4 : le compteur nbLecteursTerminés est incrémenté.
- lignes 5-6 : si tous les lecteurs ont fait leur travail, alors l'événement finLecteurs est positionné à vrai afin de prévenir la méthode Main qui attend cet événement.
- parce que la procédure EndLecteur est exécutée par plusieurs threads, la section critique précédente est protégée par la clause lock de la ligne 3.
L'exécution donne des résultats analogues à ceux de la version utilisant des threads.
XI-H-2. Exemple 2▲
Le code suivant illustre d'autres points de la classe BackgroundWorker :
- la possibilité d'annuler la tâche
- la remontée d'une exception lancée dans la tâche
- le passage d'un paramètre d'E/S à la tâche
- ligne 9 : le tableau de BackgroundWorker
- lignes 18-27 : création des threads
- ligne 20 : création du thread
- ligne 22 : le thread exécutera la méthode Sleep des lignes 39-41
- ligne 23 : la méthode End des lignes 43-45 sera exécutée à la fin du thread
- ligne 24 : le thread pourra être annulé
- ligne 26 : le thread est lancé avec un paramètre de type [Data], défini lignes 49-52. Cet objet a les champs suivants :
- Numéro (entrée) : n° du thread
- Début (entrée) : heure de début d'exécution du thread
- Durée (entrée) : durée d'exécution du Sleep
- Fin (sortie) : fin d'exécution du thread
- ligne 29 : le thread n° 4 est annulé
Tous les threads exécutent la méthode Sleep suivante :
- ligne 1 : la méthode Sleep a la signature standard des gestionnaires d'événements. Elle reçoit deux paramètres :
- sender : l'émetteur de l'événement, ici le BackgroundWorker qui exécute la méthode
- infos : de type DoWorkEventArgs qui donne des informations sur l'événement DoWork. Ce paramètre sert aussi bien à transmettre des informations au thread qu'à récupérer ses résultats.
- ligne 3 : le paramètre passé à la méthode RunWorkerAsync de la tâche est retrouvé dans la propriété infos.Argument.
- lignes 5-7 : on lance une exception pour la tâche n° 3
- lignes 9-12 : le thread "dort" Durée secondes par tranches d'une seconde afin de permettre le test d'annulation de la ligne 9. Cela simule un travail de longue durée au cours duquel le thread vérifierait régulièrement s'il existe une demande d'annulation. Pour indiquer qu'il a été annulé, le thread doit mettre la propriété infos.Cancel à vrai (ligne 17).
- ligne 16 : le thread peut rendre un résultat au thread qui l'a lancé. Il place ce résultat dans infos.Result.
Une fois terminés, les threads exécutent la méthode End suivante :
- ligne 1 : la méthode End a la signature standard des gestionnaires d'événements. Elle reçoit deux paramètres :
- sender : l'émetteur de l'événement, ici le BackgroundWorker qui exécute la méthode
- infos : de type RunWorkerCompletedEventArgs qui donne des informations sur l'événement RunWorkerCompleted.
- ligne 4 : le champ infos.Error de type Exception est renseigné seulement si une exception s'est produite.
- ligne 7 : le champ infos.Cancelled de type booléen à la valeur true si le thread a été annulé.
- ligne 8 : s'il y a pas eu exception ou annulation, alors infos.Result est le résultat du thread exécuté. Utiliser ce résultat s'il y a eu annulation du thread ou si le thread a lancé une exception, provoque une exception. Ainsi lignes 5 et 13, on n'est pas capables d'afficher le n° du thread annulé ou qui a lancé une exception car ce n° est dans infos.Result. Ce problème peut être contourné en dérivant la classe BackgroundWorker pour y mettre les informations à échanger entre le thread appelant et le thread appelé comme il a été fait dans l'exemple précédent. On utilise alors l'argument sender qui représente le BackgroundWorker au lieu de l'argument infos.
Les résultats d'exécution sont les suivants :
XI-I. Données locales à un thread▲
XI-I-1. Le principe▲
Considérons une application à trois couches :

Supposons que l'application soit multiutilisateurs, une application web par exemple. Chaque utilisateur est servi par un thread qui lui est dédié. La vie du thread est la suivante :
- le thread est créé ou demandé à un pool de threads pour satisfaire une demande d'un utilisateur
- si cette demande nécessite des données, le thread va exécuter une méthode de la couche [ui] qui va appeler une méthode de la couche [metier] qui va à son tour appeler une méthode de la couche [dao].
- le thread rend la réponse à l'utilisateur. Il disparaît ensuite ou il est recyclé dans un pool de threads.
Dans l'opération 2, il peut être intéressant que le thread ait des données qui lui soient propres, c.a.d. non partagées avec les autres threads. Ces données pourraient par exemple appartenir à l'utilisateur particulier que le thread sert. Ces données pourraient alors être utilisées dans les différentes couches [ui, metier, dao].
La classe Thread permet ce scénario grâce à une sorte de dictionnaire privé où les clés seraient de type LocalDataStoreSlot :

Un modèle d'utilisation pourrait être le suivant :
- pour créer un couple (clé,valeur) associé au thread courant :
- pour récupérer la valeur associée à clé :
XI-I-2. Application du principe▲
Considérons l'application à trois couches suivantes :

Supposons que la couche [dao] gère une base d'articles et que son interface soit initialement la suivante :
- ligne 5 : pour insérer un article dans la base
- ligne 6 : pour récupérer tous les articles de la base
- ligne 7 : pour supprimer tous les articles de la base
Ultérieurement, apparaît le besoin d'une méthode pour insérer un tableau d'articles à l'aide d'une transaction parce qu'on souhaite fonctionner en tout ou rien : soit tous les articles sont insérés soit aucun. On peut alors modifier l'interface pour intégrer ce nouveau besoin :
- ligne 6 : pour ajouter un tableau d'articles dans la base
Ultérieurement, pour une autre application, apparaît le besoin de supprimer une liste d'articles enregistrée dans une liste, toujours dans une transaction. On voit que pour répondre à des besoins métier différents, la couche [dao] va être amenée à grossir. On peut prendre une autre voie :
- ne mettre dans la couche [dao] que les opérations basiques InsertArticle, DeleteArticle, UpdateArticle, SelectArticle, SelectArticles
- déporter dans la couche [métier] les opérations de mise à jour simultanée de plusieurs articles. Celles-ci utiliseraient les opérations élémentaires de la couche [dao].
L'avantage de cette solution est que la même couche [dao] pourrait être utilisée sans changement avec différentes couches [metier]. Elle amène une difficulté dans la gestion de la transaction qui regroupe des mises à jour à faire de façon atomique sur la base :
- la transaction doit être initiée par la couche [metier] avant qu'elle n'appelle les méthodes de la couche [dao]
- les méthodes de la couche [dao] doivent connaître l'existence de la transaction afin d'y prendre part si elle existe
- la transaction doit êter terminée par la couche [métier].
Pour que les méthodes de la couche [dao] connaissent l'existence d'une éventuelle transaction en cours, on pourrait ajouter la transaction comme paramètre de chaque méthode de la couche [dao]. Ce paramètre va alors apparaître dans la signature des méthodes de l'interface, ce qui va lier celle-ci à une source de données particulière : la base de données. Les données locales du thread nous apportent une solution plus élégante : la couche [métier] mettra la transaction dans les données locales du thread et c'est là que la couche [dao] ira la chercher. La signature des méthodes de la couche [dao] n'a alors pas besoin d'être changée.
Nous mettons en œuvre cette solution avec le projet Visual studio suivant :

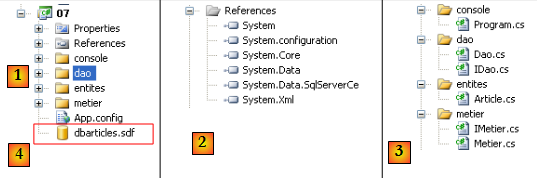
- en [1] : la solution dans son ensemble
- en [2] : les références utilisées. La base [4] étant une base SQL Server Compact, il est nécessaire d'avoir la référence [System.Data.SqlServerCe].
- en [3] : les différentes couches de l'application.
La base [4] est la base SQL Server Compact déjà utilisée dans le chapitre précédent notamment au paragraphe , page .
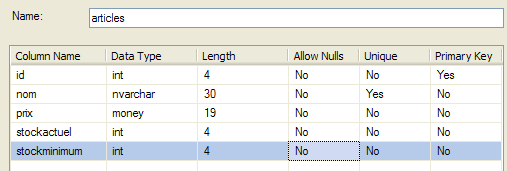
La classe Article
Une ligne de la table [articles] précédente est encapsulée dans un objet de type Article :
Interface de la couche [dao]
L'interface IDao de la couche [dao] sera la suivante :
- ligne 5 : pour insérer un article dans la table [articles]
- ligne 6 : pour mettre toutes les lignes de la table [articles] dans une liste d'objets Article
- ligne 7 : pour supprimer toutes les lignes de la table [articles]
Interface de la couche [metier]
L'interface IMetier de la couche [metier] sera la suivante :
- ligne 5 : pour insérer, à l'intérieur d'une transaction, un ensemble d'articles
- ligne 6 : idem mais sans transaction
- ligne 7 : pour obtenir la liste de tous les articles
- ligne 8 : pour supprimer tous les articles
Implémentation de la couche [metier]
L'implémentation Metier de l'interface IMetier sera la suivante :
La classe a les propriétés suivantes :
- ligne 9 : une référence sur la couche [dao]
- ligne 11 : la chaîne de connexion qui permet de se connecter à la base de données des articles
Nous ne commentons que la méthode InsertArticlesInTransaction qui seule présente des difficultés :
- ligne 16 : une connexion avec la base est créée
- ligne 18 : elle est ouverte
- ligne 23 : une transaction est créée
- ligne 25 : elle est enregistrée dans les données locales du thread, associée à la clé "transaction"
- lignes 27-29 : la méthode d'insertion unitaire de la couche [dao] est appelée pour chaque article à insérer
- lignes 21 et 32 : l'ensemble de l'insertion du tableau est contrôlée par un try / catch
- ligne 31 : si on arrive là, c'est qu'il n'y a pas eu d'exception. On valide alors la transaction.
- lignes 34-35 : il y a eu exception, on défait la transaction
- ligne 37 : on sort de la clause using. La connexion ouverte en ligne 18 est automatiquement fermée.
Implémentation de la couche [dao]
L'implémentation Dao de l'interface IDao sera la suivante :
La classe a les propriétés suivantes :
- ligne 9 : la chaîne de connexion qui permet de se connecter à la base de données des articles
- ligne 11 : l'ordre SQL pour insérer un article
- ligne 12 : l'ordre SQL pour suprrimer tous les articles
- ligne 13 : l'ordre SQL pour obtenir tous les articles
Ces propriétés seront initialisées à partir du fichier de configuration [App.config] suivant :
Nous commentons la méthode InsertArticle :
- ligne 20 : on récupère l'éventuelle transaction qu'a pu placer la couche [metier] dans le thread
- lignes 23-25 : si la transaction est présente, on récupère la connexion à laquelle elle a été liée.
- lignes 26-30 : sinon, une connexion nouvelle est créée et ouverte.
- lignes 33-44 : on prépare la commande d'insertion. Celle-ci est paramétrée (cf ligne g de App.config).
- ligne 33 : l'objet Command est créé.
- ligne 34 : il est associé à la transaction courante. Si celle-ci n'existe pas (transaction=null), cela revient à exécuter l'ordre SQL sans transaction explicite. On rappelle qu'alors il y a quand même une transaction implicite. Avec SQL Server CE, cette transaction implicite est par défaut en mode autocommit : l'ordre SQL est committé après son exécution.
- ligne 35 : l'objet Command est associé à la connexion courante
- ligne 36 : le texte SQl à exécuter est fixé. C'est la requête paramétrée de la ligne g de App.config.
- lignes 37-44 : les 4 paramètres de la requête sont initialisés
- ligne 46 : la requête est exécutée.
- lignes 49-51 : il faut se souvenir que s'il n'y avait pas de transaction, une nouvelle connexion a été ouverte avec la base, lignes 26-30. Dans ce cas, elle doit être fermée. S'il y avait une transaction, la connexion ne doit pas être fermée car c'est la couche [metier] qui la gère.
Les deux autres méthodes reprennent ce qui a été vu dans le chapitre "Bases de données" :
L'application [console] de test
L'application [console] de test est la suivante :
- lignes 12-22 : le fichier [App.config] est exploité.
- lignes 24-28 : la couche [dao] est instanciée et initialisée
- lignes 30-32 : il est fait de même pour la couche [metier]
- lignes 34-37 : on crée un tableau de 2 articles avec le même nom. La table [articles] de la base SQL server Ce [dbarticles.sdf] a une contrainte d'unicité sur le nom. L'insertion du 2ième article sera donc refusée. Si l'insertion du tableau se fait hors transaction, le 1er article sera d'abord inséré puis le restera. Si l'insertion du tableau se fait dans une transaction, le 1er article sera d'abord inséré puis sera retiré, lors du Rollback de la transaction.
- lignes 39-50 : insertion hors transaction du tableau de 2 articles et vérification.
- lignes 52-59 : idem mais dans une transaction
Les résultats à l'exécution sont les suivants :
- lignes 5-6 : l'insertion hors transaction a laissé le 1er article dans la base
- ligne 9 : l'insertion faite dans une transaction n'a laissé aucun article dans la base
XI-I-3. Conclusion▲
L'exemple précédent a montré l'intérêt des données locales à un thread pour la gestion des transactions. Il n'est pas à reproduire tel quel. Des frameworks tels que Spring, Nhibernate… utilisent cette technique mais la rendent encore plus transparente : il est possible pour la couche [metier] d'utiliser des transactions sans que la couche [dao] n'ait besoin de le savoir. Il n'y a alors aucun objet Transaction dans le code de la couche [dao]. Cela est obtenu au moyen d'une technique de proxy appelée AOP (Aspects Oriented Programming). De nouveau on ne peut qu'inciter le lecteur à utiliser ces frameworks.
XI-J. Pour approfondir…▲
Pour approfondir le domaine difficile de la synchronisation de threads, on pourra lire le chapitre Threading du livre C# 3.0 référencé dans l'introduction de ce document. On y présente de nombreuses techniques de synchronisation pour différents types de situation.
