


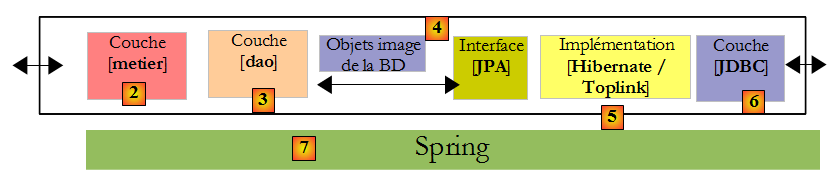
IV. JPA dans une architecture multicouches▲
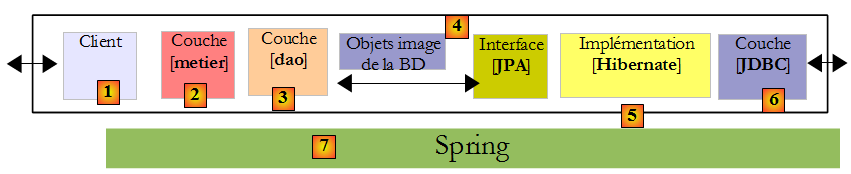
Pour étudier l'API JPA, nous avons utilisé l'architecture de test suivante :

Nos programmes de tests étaient des applications console qui interrogaient directement la couche JPA. Nous avons découvert à cette occasion les principales méthodes de la couche JPA. Nous étions dans un environnement dit "Java SE" (Standard Edition). JPA fonctionne à la fois dans un environnement Java SE et Java EE5 (Edition Entreprise).
Maintenant que nous avons une certaine maîtrise à la fois de la configuration du pont relationnel / objet et de l'utilisation des méthodes de la couche JPA, nous revenons à une architecture multicouches plus classique :
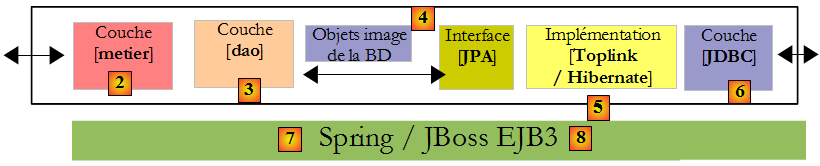
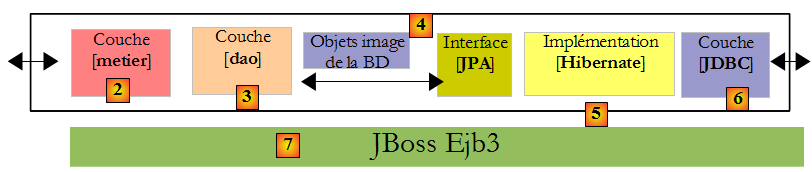
La couche [JPA] sera accédée via une architecture à 2 couches [metier] et [dao]. Le framework Spring [7], puis le conteneur EJB3 de JBoss [8] seront utilisés pour lier ces couches entre-elles.
Nous avons dit plus haut que JPA était disponible dans les environnements SE et EE5. L'environnement Java EE5 délivre de nombreux services dans le domaine de l'accès aux données persistantes notamment les pools de connexion, les gestionnaire de transactions… Il peut être intéressant pour un développeur de profiter de ces services. L'environnement Java EE5 n'est pas encore très répandu (mai 2007). On le trouve actuellement sur le serveurs d'application Sun Application Server 9.x (Glassfish). Un serveur d'application est essentiellement un serveur d'applications web. Si on construit une application graphique autonome de type Swing, on ne peut disposer de l'environnement EE et des services qu'il apporte. C'est un problème. On commence à voir des environnements EE "stand-alone", c.a.d. pouvant être utilisés en-dehors d'un serveur d'applications. C'est le cas de JBos EJB3 que nous allons utiliser dans ce document.
Dans un environnement EE5, les couches sont implémentées par des objets appelés EJB (Enterprise Java Bean). Dans les précédentes versions d'EE, les EJB (EJB 2.x) sont réputés difficiles à mettre en œuvre, à tester et parfois peu-performants. On distingue les EJB2.x "entity" et les EJB2.x "session". Pour faire court, un EJB2.x "entity" est l'image d'une ligne de table de base de données et EJB2.x "session" un objet utilisé pour implémenter les couches [metier], [dao] d'une architecture multicouches. L'un des principaux reproches faits aux couches implémentées avec des EJB est qu'elles ne sont utilisables qu'au sein de conteneurs EJB, un service délivré par l'environnement EE. Cela rend problématiques les tests unitaires. Ainsi dans le schéma ci-dessus, les tests unitaires des couches [metier] et [dao] construits avec des EJB nécessiteraient la mise en place d'un serveur d'application, une opération assez lourde qui n'incite pas vraiment le développeur à faire fréquemment des tests.
Le framework Spring est né en réaction à la complexité des EJB2. Spring fournit dans un environnement SE un nombre important des services habituellement fournis par les environnements EE. Ainsi dans la partie "Persistance de données" qui nous intéresse ici, Spring fournit les pools de connexion et les gestionnaires de transactions dont ont besoin les applications. L'émergence de Spring a favorisé la culture des tests unitaires, devenus d'un seul coup beaucoup plus faciles à mettre en œuvre. Spring permet l'implémentation des couches d'une application par des objets Java classiques (POJO, Plain Old/Ordinary Java Object), permettant la réutilisation de ceux-ci dans un autre contexte. Enfin, il intègre de nombreux outils tiers de façon assez transparente, notamment des outils de persistance tels que Hibernate, Ibatis…
Java EE5 a été conçu pour corriger les lacunes de la précédente spécification EE. Les EJB 2.x sont devenus les EJB3. Ceux-ci sont des POJOs tagués par des annotations qui en font des objets particuliers lorsqu'ils sont au sein d'un conteneur EJB3. Dans celui-ci, l'EJB3 va pouvoir bénéficier des services du conteneur (pool de connexions, gestionnaire de transactions…). En-dehors du conteneur EJB3, l'EJB3 devient un objet Java normal. Ses annotations EJB sont ignorées.
Ci-dessus, nous avons représenté Spring et JBoss EJB3 comme infrastructure (framework) possible de notre architecture multicouches. C'est cette infrastructure qui délivrera les services dont nous avons besoin : un pool de connexions et un gestionnaire de transactions.
- avec Spring, les couches seront implémentées avec des POJOs. Ceux-ci auront accès aux services de Spring (pool de connexions, gestionnaire de transaction) par injection de dépendances dans ces POJOs : lors de la construction de ceux-ci, Spring leur injecte des références sur les services dont il vont avoir besoin.
- JBoss EJB3 est un conteneur EJB pouvant fonctionner en-dehors d'un serveur d'application. Son principe de fonctionnement (pour le développeur) est analogue à celui décrit pour Spring. Nous trouverons peu de différences.
Nous terminerons le document avec un exemple d'application web à trois couches, basique mais néanmoins représentative :
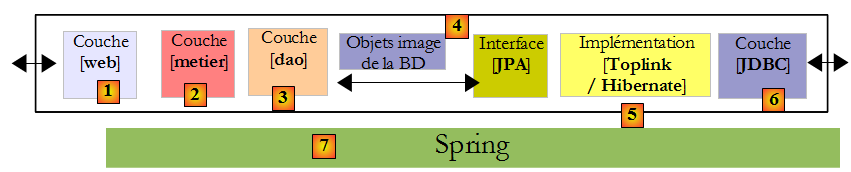
IV-A. Exemple 1 : Spring / JPA avec entité Personne▲
Nous prenons l'entité Personne étudiée au paragraphe , page et nous l'intégrons dans une architecture multicouches où l'intégration des couches est faite avec Spring et la couche de persistance est implémentée par Hibernate.
Le lecteur est ici supposé avoir des connaissances de base sur Spring. Si ce n'était pas le cas, on pourra lire le document suivant qui explique la notion d'injection de dépendances qui est au cœur de Spring :
[ref3] : Spring Ioc (Inversion Of Control) [http://tahe.developpez.com/java/springioc].
IV-A-1. Le projet Eclipse / Spring / Hibernate▲
Le projet Eclipse est le suivant :
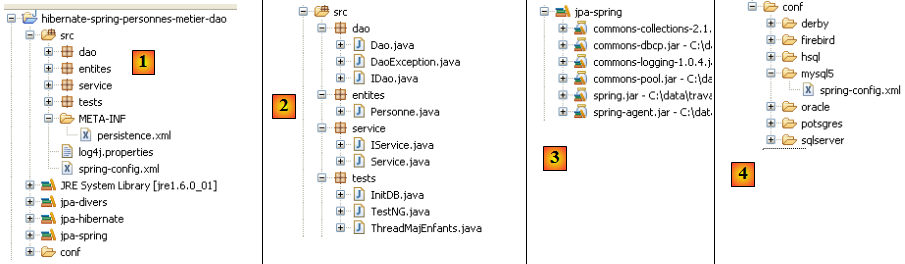
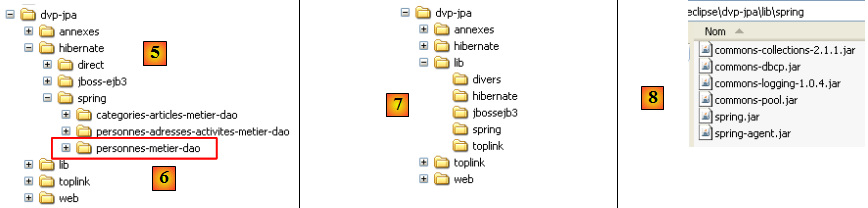
- en [1] : le projet Eclipse. Il sera trouvé en [6] dans les exemples du tutoriel [5]. On l'importera.
- en [2] : les codes Java des couches présentés en paquetages :
- [entites] : le paquetage des entités JPA
- [dao] : la couche d'accès aux données - s'appuie sur la couche JPA
- [service] : une couche de services plus que de métier. On y utilisera le service de transactions des conteneurs.
- [tests] : regroupe les programmes de tests.
- en [3] : la bibliothèque [jpa-spring] regroupe les jars nécessaires à Spring (voir aussi [7] et [8]).
- en [4] : le dossier [conf] rassemble les fichiers de configuration de Spring pour chacun des SGBD utilisés dans ce tutoriel.
IV-A-2. Les entités JPA▲

Il n'y a qu'une entité gérée ici, l'entité Personne étudiée au paragraphe , page , et dont nous rappelons ci-dessous la configuration :
IV-A-3. La couche [dao]▲

La couche [dao] présente l'interface IDao suivante :
L'implémentation [Dao] de cette interface est la suivante :
- tout d'abord, on notera la simplicité de l'implémentation [Dao]. Celle-ci est due à l'utilisation de la couche JPA qui fait l'essentiel du travail d'accès aux données.
- ligne 10 : la classe [Dao] implémente l'interface [IDao]
- ligne 13 : l'objet de type [EntityManager] qui va être utilisé pour manipuler le contexte de persistance JPA. Par abus de langage, nous le confondrons parfois avec le contexte de persistance lui-même. Le contexte de persistance contiendra des entités Personne.
- ligne 12 : nulle part dans le code, le champ [EntityManager em] n'est initialisé. Il le sera au démarrage de l'application par Spring. C'est l'annotation JPA @PersistenceContext de la ligne 12 qui demande à Spring d'injecter dans em, un gestionnaire de contexte de persistance.
- lignes 26-28 : la liste de toutes les personnes est obtenue par une requête JPQL.
- lignes 32-35 : la liste de toutes les personnes ayant un nom correspondant à un certain modèle est obtenue par une requête JPQL.
- lignes 38-40 : la personne ayant tel identifiant est obtenue par la méthode find de l'API JPA. Rend un pointeur null si la personne n'existe pas.
- lignes 43-46 : une personne est rendue persistante par la méthode persist de l'API JPA. La méthode rend la personne persistante.
- lignes 49-51 : la mise à jour d'une personne est réalisée par la méthode merge de l'API JPA. Cette méthode n'a de sens que si la personne ainsi mise à jour était auparavant détachée. La méthode rend la personne persistante ainsi créée.
- lignes 16-22 : la suppression de la personne dont on nous passe l'identifiant en pramètre se fait en deux temps :
- ligne 17 : elle est cherchée dans le contexte de persistance
- lignes 18-20 : si on ne la trouve pas, on lance une exception avec un code erreur 2
- ligne 21 : si on l'a trouvée on l'enlève du contexte de persistance avec la méthode remove de l'API JPA.
- ce qui n'est pas visible pour l'instant est que chaque méthode sera exécutée au sein d'une transaction démarrée par la couche [service].
L'application a son propre type d'exception nommé [DaoException] :
- ligne 4 : [DaoException] dérive de [RuntimeException]. C'est donc un type d'exceptions que le compilateur ne nous oblige pas à gérer par un try / catch ou à mettre dans la signture des méthodes. C'est pour cette raison, que [DaoException] n'est pas dans la signature de la méthode [deleteOne] de l'interface [IDao]. Cela permet à cette interface d'être implémentée par une classe lançant un autre type d'exceptions pourvu que celui-ci dérive égaleemnt de [RuntimeException].
- pour différencier les erreurs qui peuvent se produire, on utilise le code erreur de la ligne 7. Les trois constructeurs des lignes 14, 19 et 24 sont ceux de la classe parente [RuntimeException] auxquels on a rajouté un paramètre : celui du code d'erreur qu'on veut donner à l'exception.
IV-A-4. La couche [metier / service]▲

La couche [service] présente l'interface [IService] suivante :
- lignes 8-24 : l'interface [IService] reprend les méthodes de l'interface [IDao]
- ligne 27 : la méthode [deleteArray] permet de supprimer un ensemble de personnes au sein d'une transaction : toutes les personnes sont supprimées ou aucune.
- lignes 30 et 33 : des méthodes analogues à [deleteArray] pour sauvegarder (ligne 30) ou mettre à jour (ligne 33) un ensemble de personnes au sein d'une transaction.
L'implémentation [Service] de l'interface [IService] est la suivante :
- ligne 6 : l'annotation Spring @Transactional indique que toutes les méthodes de la classe doivent s'exécuter au sein d'une transaction. Une transaction sera commencée avant le début d'exécution de la méthode et fermée après exécution. Si une exception de type [RuntimeException] ou dérivé se produit au cours de l'exécution de la méthode, un rollback automatique annule toute la transaction, sinon un commit automatique la valide. On retiendra que le code Java n'a pas besoin de se soucier des transactions. Elles sont gérées par Spring.
- ligne 10 : une référence sur la couche [dao]. Nous verrons ultérieurement que cette référence est initialisée par Spring au démarrage de l'application.
- les méthodes de [Service] se contentent d'appeler les méthodes de l'interface [IDao dao] de la ligne 10. Nous laissons le lecteur prendre connaissance du code. Il n'y a pas de difficultés particulières.
- nous avons dit précédemment que chaque méthode de [Service] s'exécutait dans une transaction. Celle-ci est attachée au thread d'exécution de la méthode. Dans ce thread, sont exécutées des méthodes de la couche [dao]. Celles-ci seront automatiquement rattachées à la transaction du thread d'exécution. La méthode [deleteArray] (ligne 21), par exemple, est amenée à exécuter N fois la méthode [deleteOne] de la couche [dao]. Ces N exécutions se feront au sein du thread d'exécution de la méthode [deleteArray], donc au sein de la même transaction. Aussi seront-elles soit toutes validées (commit) si les choses se passent bien ou toutes annulées (rollback) si une exception se produit dans l'une des N exécutions de la méthode [deleteOne] de la couche [dao].
IV-A-5. Configuration des couches▲

La configuration des couches [service], [dao] et [JPA] est assurée par deux fichiers ci-dessus : [META-INF/persistence.xml] et [spring-config.xml]. Les deux fichiers doivent être dans le classpath de l'application, ce qui explique qu'ils soient dans le dossier [src] du projet Eclipse. Le nom du fichier [spring-config.xml] est libre.
persistence.xml
- ligne 4 : le fichier déclare une unité de persistance appelée jpa qui utilise des transactions "locales", c.a.d. non fournies par un conteneur EJB3. Ces transactions sont créées et gérées par Spring et font l'objet de configurations dans le fichier [spring-config.xml].
spring-config.xml
- lignes 2-5 : la balise racine <beans> du fichier de configuration. Nous ne commentons pas les divers attributs de cette balise. On prendra soin de faire un copier / coller parce que se tromper dans l'un de ces attributs provoque des erreurs parfois difficiles à comprendre.
- ligne 8 : le bean "dao" est une référence sur une instance de la classe [dao.Dao]. Une instance unique sera créée (singleton) et implémentera la couche [dao] de l'application.
- lignes 9-11 : instanciation de la couche [service]. Le bean "service" est une référence sur une instance de la classe [service.Service]. Une instance unique sera créée (singleton) et implémentera la couche [service] de l'application. Nous avons vu que la classe [service.Service] avait un champ privé [IDao dao]. Ce champ est initialisé ligne 10 par le bean "dao" défini ligne 8.
- finalement les lignes 8-11 ont configuré les couches [dao] et [service]. Nous verrons plus loin à quel moment et comment elles seront instanciées.
- lignes 35-42 : une source de données est définie. Nous avons déjà rencontré la notion de source de données lors de l'étude des entités JPA avec Hibernate :

Ci-dessus, [c3p0] appelé "pool de connexions" aurait pu être appelé "source de données". Une source de données fournit le service de "pool de connexions". Avec Spring, nous utiliserons une source de données autre que [c3p0]. C'est [DBCP] du projet Apache commons DBCP [http://jakarta.apache.org/commons/dbcp/]. Les archives de [DBCP] ont été placées dans la bibliothèque utilisateur [jpa-spring] :
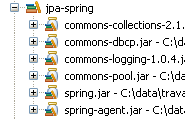
|
- lignes 38-41 : pour créer des connexions avec la base de données cible, la source de données a besoin de connaître le pilote Jdbc utilisé (ligne 38), l'url de la base de données (ligne 39), l'utilisateur de la connexion et son mot de passe (lignes 40-41).
- lignes 14-32 : configurent la couche JPA
- lignes 14-15 : définissent un bean de type [EntityManagerFactory] capable de créer des objets de type [EntityManager] pour gérer les contextes de persistance. La classe instanciée [LocalContainerEntityManagerFactoryBean] est fournie par Spring. Elle a besoin d'un certain nombre de paramètres pour s'instancier, définis lignes 16-31.
- ligne 16 : la source de données à utiliser pour obtenir des connexions au SGBD. C'est la source [DBCP] définie aux lignes 35-42.
- lignes 17-27 : l'implémentation JPA à utiliser
- lignes 18-26 : définissent Hibernate (ligne 19) comme implémentation JPA à utiliser
- lignes 23-24 : le dialecte SQL qu'Hibernate doit utiliser avec le SGBD cible, ici MySQL5.
- ligne 25 : demande qu'au démarrage de l'application, la base de données soit générée (drop et create).
- lignes 28-31 : définissent un "chargeur de classes". Je ne saurai pas expliquer de façon claire le rôle de ce bean utilisé par l'EntityManagerFactory de la couche JPA. Toujours est-il, qu'il implique de passer à la JVM qui exécute l'application, le nom d'une archive dont le contenu va gérer le chargement des classes au démarrage de l'application. Ici, cette archive est [spring-agent.jar] placée dans la bibliothèque utilisateur [jpa-spring] (voir plus haut). Nous verrons qu'Hibernate n'a pas besoin de cet agent mais que Toplink lui en a besoin.
- lignes 45-50 : définissent le gestionnaire de transactions à utiliser
- ligne 45 : indique que les transactions sont gérées avec des annotations Java (elles auraient pu être également déclarées dans spring-config.xml). C'est en particulier l'annotation @Transactional rencontrée dans la classe [Service] (ligne 6).
- lignes 46-50 : le gestionnaire de transactions
- ligne 47 : le gestionnaire de transactions est une classe fournie par Spring
- lignes 48-49 : le gestionnaire de transactions de Spring a besoin de connaître l'EntityManagerFactory qui gère la couche JPA. C'est celui défini aux lignes 14-32.
- lignes 57-58 : définissent la classe qui gère les annotations de persistance Spring trouvées dans le code Java, telles l'annotation @PersistenceContext de la classe [dao.Dao] (ligne 12).
- lignes 53-54 : définissent la classe Spring qui gère notamment l'annotation @Repository qui rend une classe ainsi annotée, éligible pour la traduction des exceptions natives du pilote Jdbc du SGBD en exceptions génériques Spring de type [DataAccessException]. Cette traduction encapsule l'exception Jdbc native dans un type [DataAccessException] ayant diverses sous-classes :

Cette traduction permet au programme client de gérer les exceptions de façon générique quelque soit le SGBD cible. Nous n'avons pas utilisé l'annotation @Repository dans notre code Java. Aussi les lignes 53-54 sont-elles inutiles. Nous les avons laissées par simple souci d'information.
Nous en avons fini avec le fichier de configuration de Spring. Il est complexe et bien des choses restent obscures. Il a été tiré de la documentation Spring. Heureusement, son adaptation à diverses situations se résume souvent à deux modifications :
- celle de la base de données cible : lignes 38-41. Nous donnerons un exemple Oracle.
- celle de l'implémentation JPA : lignes 14-32. Nous donnerons un exemple Toplink.
IV-A-6. Programme client [InitDB]▲
Nous abordons l'écriture d'un premier client de l'architecture décrite précédemment :
Le code de [InitDB] est le suivant :
- ligne 12 : le fichier [spring-config.xml] est exploité pour créer un objet [ApplicationContext ctx] qui est une image mémoire du fichier. Les beans définis dans [spring-config.xml] sont instanciés à cette occasion.
- ligne 14 : on demande au contexte d'application ctx une référence sur la couche [service]. On sait que celle-ci est représentée par un bean s'appelant "service".
- ligne 16 : la base est vidée au moyen de la méthode clean des lignes 41-45 :
- lignes 42-44 : on demande la liste de toutes les personnes au contexte de persistance et on boucle sur elles pour les supprimer une à une. On se rappelle peut-être que [spring-config.xml] précise que la base de données doit être générée au démarrage de l'application. Aussi dans notre cas, l'appel de la méthode clean est inutile puisqu'on part d'une base vide.
- ligne 18 : la méthode fill remplit la base. Celle-ci est définie lignes 32-38 :
- lignes 34-35 : deux personnes sont créées
- ligne 37 : on demande à la couche [service] de les rendre persistantes.
- ligne 20 : la méthode dumpPersonnes affiche les personnes persistantes. Elle est définie aux lignes 24-29
- lignes 26-28 : on demande la liste de toutes les personnes persistantes à la couche [service] et on les affiche sur la console.
L'exécution de [InitDB] donne le résultat suivant :
IV-A-7. Tests unitaires [TestNG]▲
L'installation du plugin [TestNG] est décrite au paragraphe , page . Le code du programme [TestNG] est le suivant :
- ligne 9 : l'annotation @BeforeClass désigne la méthode à exécuter pour initialiser la configuration nécessaire aux tests. Elle est exécutée avant que le premier test ne soit exécuté. L'annotation @AfterClass non utilisée ici, désigne la méthode à exécuter une fois que tous les tests ont été exécutés.
- lignes 10-17 : la méthode init annotée par @BeforeClass exploite le fichier de configuration de Spring pour instancier les différentes couches de l'application et avoir une référence sur la couche [service]. Tous les tests utilisent ensuite cette référence.
- ligne 19 : l'annotation @BeforeMethod désigne la méthode à exécuter avant chaque test. L'annotation @AfterMethod, non utilisée ici, désigne la méthode à exécuter après chaque test.
- lignes 20-25 : la méthode setUp annotée par @BeforeMethod vide la base (clean lignes 52-56) puis la remplit avec deux personnes (fill lignes 42-49).
- ligne 59 : l'annotation @Test désigne une méthode de test à exécuter. Nous décrivons maintenant ces tests.
- lignes 2-8 : le test 01. Il faut se rappeler qu'au départ de chaque test, la base contient deux personnes de noms respectifs p1 et p2.
- ligne 6 : on demande la liste des personnes
- lignes 7 : on vérifie que le nombre de personnes de la liste obtenue est 2
- ligne 14 : on demande la liste des personnes ayant un nom commençant par p1
- on vérifie que la liste obtenue n'a qu'un élément (ligne 15) et que le prénom de l'unique personne obtenue est "Paul" (ligne 17)
- ligne 24 : on crée une personne nommée p3
- ligne 25 : on la persiste
- ligne 28 : on la redemande au contexte de persistance pour vérification
- ligne 32 : on vérifie que la personne obtenue a bien le nom p3.
- ligne 5 : on demande la personne p1
- ligne 10 : on vérifie son nom
- ligne 11 : on note son n° de version
- ligne 13 : on modifie son prénom
- ligne 15 : on sauvegarde la modification
- ligne 17 : on redemande la personne p1
- ligne 21 : on vérifie que son n° de version a augmenté de 1
- ligne 5 : on demande la personne p2
- ligne 10 : on vérifie son nom
- ligne 12 : on la supprime
- ligne 14 : on la redemande
- ligne 16 : on vérifie qu'on ne l'a pas trouvée
- ligne 5 : on crée un tableau de trois personnes dont deux ont le même nom "p4". Cela enfreint la règle d'unicité du nom de l'@Entity Personne :
- ligne 11 : le tableau des trois personnes est mis dans le contexte de persistance. L'ajout de la seconde personne p4 devrait échouer. Comme la méthode [saveArray] se déroule dans une transaction, toutes les insertions qui ont pu être faites avant seront annulées. Au final, aucun ajout ne sera fait.
- ligne 18 : on vérifie que [saveArray] a bien lancé une exception
- lignes 20-21 : on vérifie que la personne p3 qui aurait pu être ajoutée ne l'a pas été.
- ligne 6 : on demande la personne p1
- ligne 12 : on augmente de 1 son nombre d'enfants
- ligne 14 : on met à jour la personne p1 dans le contexte de persistance. La méthode [updateOne] rend la nouvelle version newp1 persistante de p1. Elle diffère de p1 par son n° de version qui a du être incrémenté.
- ligne 15 : on vérifie le nombre d'enfants de newp1.
- ligne 21 : on redemande une mise à jour de la personne p1 à partir de l'ancienne version p1. On doit avoir une exception car p1 n'est pas la dernière version de la personne p1. Cette dernière version est newp1.
- ligne 23 : on vérifie que l'erreur a bien eu lieu
- lignes 27-35 : on vérifie que si une mise à jour est faite à partir de la dernière version newp1, alors les choses se passent bien.
- le test 8 est similaire au test 6 : il vérifie le rollback sur un updateArray opérant sur un tableau de deux personnes où la deuxième n'a pas été initialisée correctement. D'un point de vue JPA, l'opération merge sur la seconde personne qui n'existe pas déjà va générer un ordre SQL insert qui va échouer à cause des contraintes nullable=false qui existe sur certains des champs de l'entité Personne.Cacher/Afficher le codeSélectionnez
- le test 9 est similaire au précédent : il vérifie le rollback sur un deleteArray opérant sur un tableau de deux personnes où la deuxième n'existe pas. Or dans ce cas, la méthode [deleteOne] de la couche [dao] lance une exception.
- l'idée du test 10 est de lancer N threads (ligne 9) pour incrémenter en parallèle le nombre d'enfants d'une personne. On veut vérifier que le système du n° de version résiste bien à ce cas de figure. Il a été créé pour cela.
- lignes 5-6 : une personne nommée p3 est créée puis persistée. Elle a 0 enfant au départ.
- ligne 7 : on note son identifiant.
- lignes 9-14 : on lance N threads en parallèle, tous chargés d'incrémenter de 1 le nombre d'enfants de p3.
- lignes 16-18 : on attend la fin de tous les threads
- ligne 20 : on demande à voir la personne p3
- ligne 22 : on vérifie qu'elle a maintenant N enfants
- ligne 24 : la personne p3 est supprimée.
Le thread [ThreadMajEnfants] est le suivant :
- lignes 15-19 : le constructeur mémorise les informations dont il a besoin pour travailler : son nom (ligne 16), la référence sur la couche [service] qu'il doit utiliser (ligne 17) et l'identifiant de la personne p dont il doit incrémenter le nombre d'enfants (ligne 18).
- lignes 22-66 : la méthode [run] exécutée par tous les threads en parallèle.
- ligne 29 : le thread essaie de façon répétée d'incrémenter le nombre d'enfants de la personne p. Il ne s'arrête que lorsqu'il a réussi.
- ligne 31 : la personne p est demandée
- ligne 36 : son nombre d'enfants est incrémenté en mémoire
- lignes 38-47 : on fait une pause de 10 ms. Cela va permettre à d'autres threads d'obtenir la même version de la personne p. On aura donc au même moment plusieurs threads détenant la même version de la personne p et voulant la modifier. C'est ce qui est désiré.
- ligne 52 : une fois la pause terminée, le thread demande à la couche [service] de persister la modification. On sait qu'il y aura de temps en temps des exceptions, aussi a-t-on entouré l'opération d'un try / catch.
- ligne 55 : les tests montrent qu'on a des exceptions de type [javax.persistence.OptimisticLockException]. C'est normal : c'est l'exception lancée par la couche JPA lorsqu'un thread veut modifier la personne p sans avoir la dernière version de celle-ci. Cette exception est ignorée pour laisser le thread tenter de nouveau l'opération jusqu'à ce qu'il y arrive.
- ligne 57 : les tests montrent qu'on a également des exceptions de type [org.springframework.transaction.UnexpectedRollbackException]. C'est ennuyeux et inattendu. Je n'ai pas d'explications à donner. Nous voilà dépendants de Spring alors qu'on aurait voulu éviter cela. Cela signifie que si on exécute notre application dans JBoss Ejb3 par exemple, le code du thread devra être changé. L'exception Spring est ici aussi ignorée pour laisser le thread tenter de nouveau l'opération d'incrémentation.
- ligne 59 : les autres types d'exception sont remontés à l'application.
Lorsque [TestNG] est exécuté on obtient les résultats suivants :
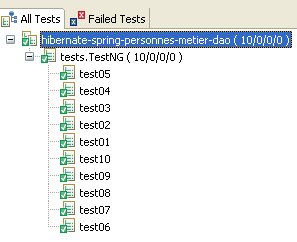
Les 10 tests ont été passés avec succès.
Le test 10 mérite des explications complémentaires parce que le fait qu'il ait réussi a un côté magique. Revenons tout d'abord sur la configuration de la couche [dao] :
- ligne 4 : un objet [EntityManager] est injecté dans le champ em grâce à l'annotation JPA @PersistenceContext. La couche [dao] est instanciée une unique fois. C'est un singleton utilisé par tous les threads utilisant la couche JPA. Ainsi donc l'EntityManager em est-il commun à tous les threads. On peut le vérifier en affichant la valeur de em dans la méthode [updateOne] utilisée par les threads [ThreadMajEnfants] : on a la même valeur pour tous les threads.
Du coup, on peut se demander si les objets persistants des différents threads manipulés par l'EntityManager em qui est le même pour tous les threads, ne vont pas se mélanger et créer des conflits entre-eux. Un exemple de ce qui pourrait se passer se trouve dans [ThreadMajEnfants] :
- ligne 3 : un thread T1 récupère la personne p
- ligne 8 : elle incrémente le nombre d'enfants de p
- ligne 14 : le thread T1 fait une pause
Un thread T2 prend la main et exécute lui aussi la ligne 3 : il demande la même personne p que T1. Si le contexte de persistance des threads était le même, la personne p étant déjà dans le contexte grâce à T1 devrait être rendue à T2. En effet, la méthode [getOne] utilise la méthode [EntityManager].find de l'API JPA et cette méthode ne fait un accès à la base que si l'objet demandé ne fait pas partie du contexte de persistance, sinon elle rend l'objet du contexte de persistance. Si tel était le cas, T1 et T2 détiendraient la même personne p. T2 incrémenterait alors le nombre d'enfants de p de 1 de nouveau (ligne 8). Si l'un des threads réussit sa mise à jour après la pause, alors le nombre d'enfants de p aura été augmenté de 2 et non de 1 comme prévu. On pourrait alors s'attendre à ce que les N threads passent le nombre d'enfants non pas à N mais à davantage. Or ce n'est pas le cas. On peut alors conclure que T1 et T2 n'ont pas la même référence p. On le vérifie en faisant afficher l'adresse de p par les threads : elle est différente pour chacun d'eux.
Il semblerait donc que les threads :
- partagent le même gestionnaire de contexte de persistance (EntityManager)
- mais ont chacun un contexte de persistance qui leur est propre.
Ce ne sont que des suppositions et l'avis d'un expert serait utile ici.
IV-A-8. Changer de SGBD▲

Pour changer de SGBD, il suffit de remplacer le fichier [src/spring-config.xml] [2] par le fichier [spring-config.xml] du SGBD concerné du dossier [conf] [1].
Le fichier [spring-config.xml] d'Oracle est, par exemple, le suivant :
Seules certaines lignes changent vis à vis du même fichier utilisé précédemment pour MySQL5 :
- ligne 14 : le dialecte SQL qu'Hibernate doit utiliser
- lignes 25-28 : les caractéristiques de la connexion Jdbc avec le SGBD
Le lecteur est invité à répéter les tests décrits pour MySQL5 avec d'autres SGBD.
IV-A-9. Changer d'implémentation JPA▲
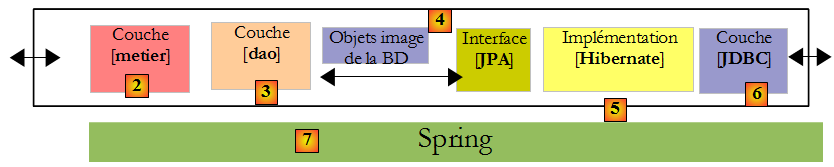
Revenons à l'architecture des tests précédents :
Nous remplaçons l'implémentation JPA / Hibernate par une implémentation JPA / Toplink. Toplink n'utilisant pas les mêmes bibliothèques qu'Hibernate, nous utilisons un nouveau projet Eclipse :
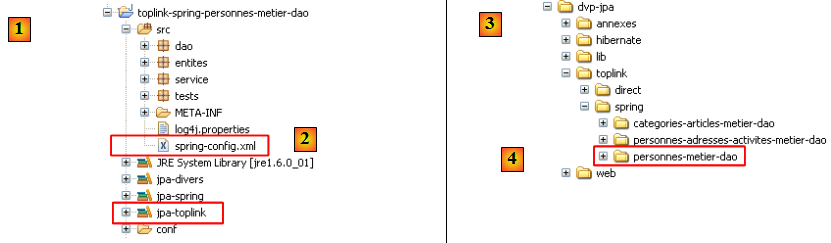
- en [1] : le projet Eclipse. Il est identique au précédent. Seuls changent le fichier de configuration [spring-config.xml] [2] et la bibliothèque [jpa-toplink] qui remplace la bibliothèque [jpa-hibernate].
- en [3] : le dossier des exemples de ce tutoriel. En [4] le projet Eclipse à importer.
Le fichier de configuration [spring-config.xml] pour Toplink devient le suivant :
Peu de lignes doivent être changées pour passer d'Hibernate à Toplink :
- ligne 19 : l'implémentation JPA est désormais faite par Toplink
- ligne 23 : la propriété [databasePlatform] a une autre valeur qu'avec Hibernate : le nom d'une classe propre à Toplink. Où trouver ce nom a été expliqué au paragraphe , page .
C'est tout. On notera la facilité avec laquelle on peut changer de SGBD ou d'implémentation JPA avec Spring.
On n'a quand même pas tout a fait fini. Lorsqu'on exécute [InitDB] par exemple, on a une exception pas simple à comprendre :
Le message d'erreur de la ligne 1 incite à lire la documentation Spring. On y découvre alors un peu plus le rôle joué par une déclaration obscure du fichier [spring-config.xml] :
La ligne 1 de l'exception fait référence à une classe nommée [InstrumentationLoadTimeWeaver], classe que l'on retrouve ligne 13 du fichier de configuration Spring. La documentation Spring explique que cette classe est nécessaire dans certains cas pour charger les classes de l'application et que pour qu'elle soit exploitée, la JVM doit être lancée avec un agent. Cet agent est fourni par Spring et s'appelle [spring-agent] :
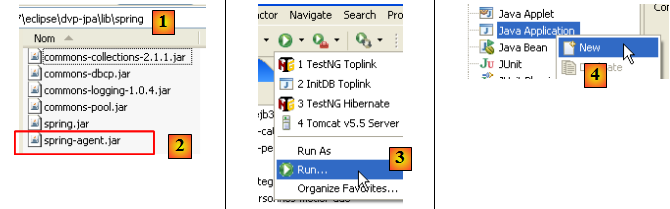
- le fichier [spring-agent.jar] est dans le dossier <exemples>/lib [1]. Il est fourni avec la distribution Spring 2.x (cf paragraphe , page ).
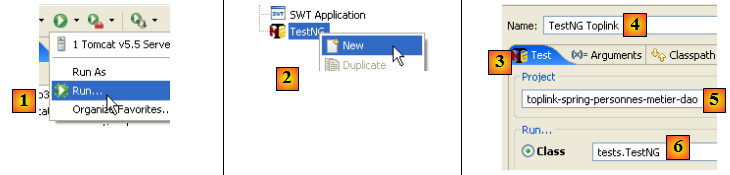
- en [3], on crée une configuration d'exécution [Run/Run…]
- en [4], on crée une configuration d'exécution Java (il y a diverses sortes de configurations d'exécution)
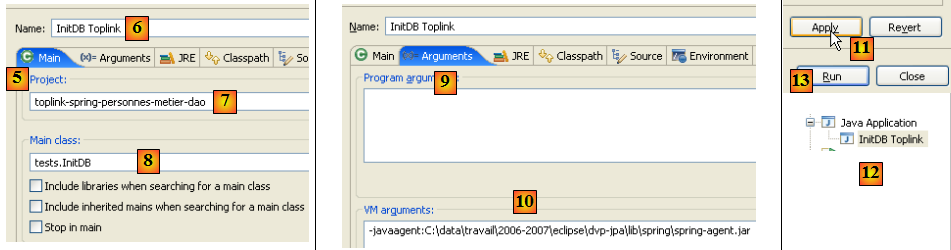
- en [5], on choisit l'onglet [Main]
- en [6], on donne un nom à la configuration
- en [7], on nomme le projet Eclipse concerné par cette configuration (utiliser le bouton Browse)
- en [8], on nomme la classe Java qui contient la méthode [main] (utiliser le bouton Browse)
- en [9], on passe dans l'onglet [Arguments]. Dans celui-ci on peut préciser deux types d'arguments :
- en [9], ceux passés à la méthode [main]
- en [10], ceux passés à la JVM qui va exécuter le code. L'agent Spring est défini à l'aide du paramètre -javaagent:valeur de la JVM. La valeur est le chemin du fichier [spring-agent.jar].
- en [11] : on valide la configuration
- en [12] : la configuration est créée
- en [13] : on l'exécute
Ceci fait, [InitDB] s'exécute et donne les mêmes résultats qu'avec Hibernate. Pour [TestNG], il faut procéder de la même façon :
- en [1], on crée une configuration d'exécution [Run/Run…]
- en [2], on crée une configuration d'exécution TestNG
- en [3], on choisit l'onglet [Test]
- en [4], on donne un nom à la configuration
- en [5], on nomme le projet Eclipse concerné par cette configuration (utiliser le bouton Browse)
- en [6], on nomme la classe des tests (utiliser le bouton Browse)
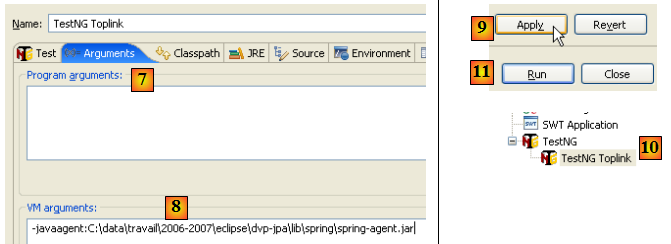
- en [7], on passe dans l'onglet [Arguments].
- en [8] : on fixe l'argument -javaagent de la JVM.
- en [9] : on valide la configuration
- en [10] : la configuration est créée
- en [11] : on l'exécute
Ceci fait, [TestNG] s'exécute et donne les mêmes résultats qu'avec Hibernate.
IV-B. Exemple 2 : JBoss EJB3 / JPA avec entité Personne▲
Nous reprenons le même exemple que précédemment, mais nous l'exécutons dans un conteneur EJB3, celui de JBoss :
Un conteneur Ejb3 est normalement intégré à un serveur d'application. JBoss délivre un conteneur Ejb3 "standalone" utilisable hors d'un serveur d'application. Nous allons découvrir qu'il délivre des services analogues à ceux délivrés par Spring. Nous essaierons de voir lequel de ces conteneurs se montre le plus pratique.
L'installation du conteneur JBoss Ejb3 est décrite au paragraphe , page .
IV-B-1. Le projet Eclipse / Jboss Ejb3 / Hibernate▲
Le projet Eclipse est le suivant :
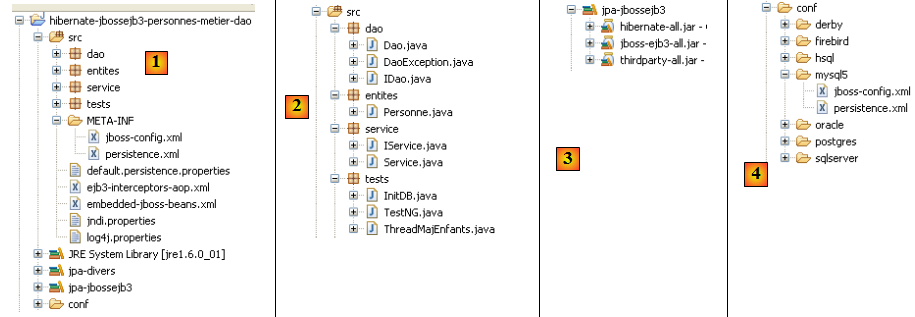
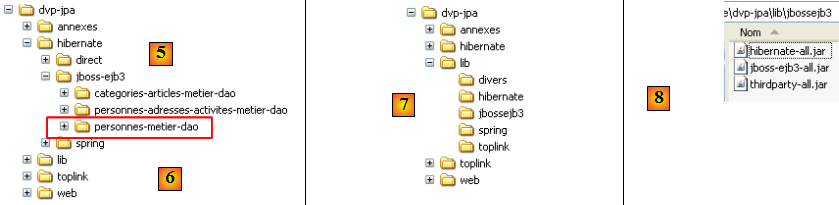
- en [1] : le projet Eclipse. Il sera trouvé en [6] dans les exemples du tutoriel [5]. On l'importera.
- en [2] : les codes Java des couches présentés en paquetages :
- [entites] : le paquetage des entités JPA
- [dao] : la couche d'accès aux données - s'appuie sur la couche JPA
- [service] : une couche de services plus que de métier. On y utilisera le service de transactions du conteneur Ejb3.
- [tests] : regroupe les programmes de tests.
- en [3] : la bibliothèque [jpa-jbossejb3] regroupe les jars nécessaires à Jboss Ejb3 (voir aussi [7] et [8]).
- en [4] : le dossier [conf] rassemble les fichiers de configuration pour chacun des SGBD utilisés dans ce tutoriel. Il y en a à chaque fois deux : [persistence.xml] qui configure la couche JPA et [jboss-config.xml] qui configure le conteneur Ejb3.
IV-B-2. Les entités JPA▲

Il n'y a qu'une entité gérée ici, l'entité Personne étudiée précédemment au paragraphe , page .
IV-B-3. La couche [dao]▲

La couche [dao] présente l'interface [IDao] décrite précédemment au paragraphe , page .
L'implémentation [Dao] de cette interface est la suivante :
- ce code est en tout point identique à celui qu'on avait avec Spring. Seules les annotations Java changent et c'est cela que nous commentons.
- ligne 4 : l'annotation @Stateless fait de la classe [Dao] un Ejb sans état. L'annotation @Stateful fait d'une classe un Ejb avec état. Un Ejb avec état a des champs privés dont il faut conserver la valeur au fil du temps. Un exemple classique est celui d'une classe qui contient des informations liées à l'utilisateur web d'une application. Une instance de cette classe est liée à un utilisateur précis et lorsque le thread d'exécution d'une requête de cet utilisateur est terminé, l'instance doit être conservée pour être disponible lors de la prochaine requête du même client. Un Ejb @Stateless n'a pas d'état. Si on reprend le même exemple, à la fin du thread d'exécution d'une requête d'un utilisateur, l'Ejb @Stateless va rejoindre un pool d'Ejb @Stateless et devient disponible pour le thread d'exécution d'une requête d'un autre utilisateur.
- pour le développeur, la notion d'Ejb3 @Stateless est proche de celle du singleton de Spring. Il l'utilisera dans les mêmes cas.
- ligne 7 : l'annotation @PersistenceContext est la même que celle rencontrée dans la version Spring de la couche [dao]. Elle désigne le champ qui va recevoir l'EntityManager qui va permettre à la couche [dao] de manipuler le contexte de persistance.
- ligne 11 : l'annotation @TransactionAttribute appliquée à une méthode sert à configurer la transaction dans laquelle va s'exécuter la méthode. Voici quelques valeurs possibles de cette annotation :
- TransactionAttributeType.REQUIRED : la méthode doit s'exécuter dans une transaction. Si une transaction a déjà démarré, les opérations de persistance de la méthode prennent place dans celle-ci. Sinon, une transaction est créée et démarrée.
- TransactionAttributeType.REQUIRES_NEW : la méthode doit s'exécuter dans une transaction neuve. Celle-ci est créée et démarrée.
- TransactionAttributeType.MANDATORY : la méthode doit s'exécuter dans une transaction existante. Si celle-ci n'existe pas, une exception est lancée.
- TransactionAttributeType.NEVER : la méthode ne s'exécute jamais dans une transaction.
- …
L'annotation aurait pu être placée sur la classe elle-même :
L'attribut est alors appliqué à toutes les méthodes de la classe.
IV-B-4. La couche [metier / service]▲

La couche [service] présente l'interface [IService] étudiée précédemment au paragraphe , page . L'implémentation [Service] de l'interface [IService] est identique à l'implémentation étudiée précédemment au paragraphe , page à trois détails près :
- ligne 2 : la classe [Service] est un Ejb sans état
- ligne 3 : toutes les méthodes de la classe [Service] doivent se dérouler dans une transaction
- lignes 7-8 : une référence sur l'Ejb de la couche [dao] sera injectée par le conteneur Ejb dans le champ [IDao dao] de la ligne 8. C'est l'annotation @EJB de la ligne 7 qui demande cette injection. L'objet injecté doit être un Ejb. C'est une différence importante avec Spring où tout type d'objet peut être injecté dans un autre objet.
IV-B-5. Configuration des couches▲
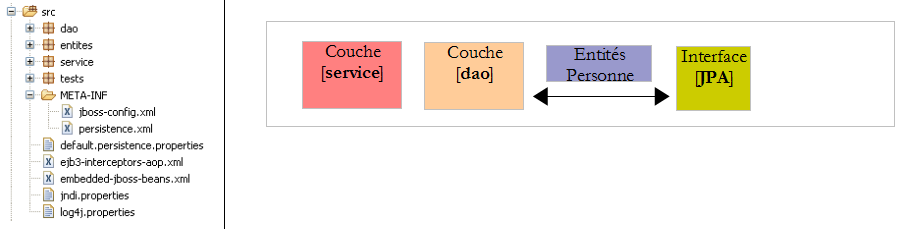
La configuration des couches [service], [dao] et [JPA] est assurée par les fichiers suivants :
- [META-INF/persistence.xml] configure la couche JPA
- [jboss-config.xml] configure le conteneur Ejb3. Il utilise lui-même les fichiers [default.persistence.properties, ejb3-interceptors-aop.xml, embedded-jboss-beans.xml, jndi.properties]. Ces derniers fichiers sont livrés avec Jboss Ejb3 et assure une configuration par défaut à laquelle on ne touche normalement pas. Le développeur ne s'intéresse qu'au fichier [jboss-config.xml]
Examinons les deux fichiers de configuration :
persistence.xml
Ce fichier ressemble à ceux que nous avons déjà rencontrés dans l'étude des entités JPA. Il configure une couche JPA Hibernate. Les nouveautés sont les suivantes :
- ligne 5 : l'unité de persistance jpa n'a pas l'attribut transaction-type qu'on avait toujours jusqu'ici :
En l'absence de valeur, l'attribut transaction-type a la valeur par défaut "JTA" (pour Java Transaction Api) qui indique que le gestionnaire de transactions est fourni par un conteneur Ejb3. Un gestionnaire "JTA" peut faire davantage qu'un gestionaire "RESOURCE_LOCAL" : il peut gérer des transactions qui couvrent plusieurs connexions. Avec JTA, on peut ouvrir une transaction t1 sur une connexion c1 sur un SGBD 1, une transaction t2 sur une connexion c2 avec un SGBD 2 et être capable de considérer (t1,t2) comme une unique transaction dans laquelle soit toutes les opérations réussissent (commit) soit aucune (rollback).
ici, nous fonctionnons avec le gestionnaire JTA du conteneur Jboss Ejb3.
- ligne 11 : déclare la source de données que doit utiliser le gestionnaire JTA. Celle-ci est donnée sous la forme d'un nom JNDI (Java Naming and Directory Interface). Cette source de données est définie dans [jboss-config.xml].
jboss-config.xml
- ligne 3 : la balise racine du fichier est <deployment>. Ce fichier de déploiement vise essentiellement à configurer la source de données java:/datasource qui a été déclarée dans persistence.xml.
- la source de données est définie par le bean "datasource" de la ligne 38. On voit que la source de données est obtenue (ligne 40) auprès d'une "factory" définie par le bean "datasourceFactory" de la ligne 7. Pour obtenir la source de données de l'application, le client devra appeler la méthode [getDatasource] de la factory (ligne 39).
- ligne 7 : la factory qui délivre la source de données est une classe Jboss.
- ligne 9 : le nom JNDI de la source de données. Ce doit être le même nom que celui déclaré dans la balise <jta-data-source> du fichier persistence.xml. En effet, la couche JPA va utiliser ce nom JNDI pour demander la source de données.
- lignes 12-15 : quelque chose de plus classique : les caractéristiques Jdbc de la connexion au SGBD
- lignes 18-21 : configuration du pool de connexions interne du conteneur Jboss Ejb3.
- lignes 24-26 : le gestionnaire JTA. La classe [TransactionManager] injectée ligne 25 est définie dans le fichier [embedded-jboss-beans.xml].
- lignes 28-30 : le cache Hibernate, une notion que nous n'avons pas abordée. La classe [CachedConnectionManager] injectée ligne 29 est définie dans le fichier [embedded-jboss-beans.xml]. On notera que la configuration est maintenant dépendante d'Hibernate, ce qui nous posera problème lorsqu'on voudra migrer vers Toplink.
- lignes 32-34 : configuration du service JNDI.
Nous en avons fini avec le fichier de configuration de Jboss Ejb3. Il est complexe et bien des choses restent obscures. Il a été tiré de [ref1]. Nous serons cependant capables de l'adapter à un autre SGBD ( lignes 12-15 de jboss-config.xml, ligne 24 de persistence.xml). La migration vers Toplink n'a pas été possible faute d'exemples.
IV-B-6. Programme client [InitDB]▲
Nous abordons l'écriture d'un premier client de l'architecture décrite précédemment :
Le code de [InitDB] est le suivant :
- la façon de lancer le conteneur Jboss Ejb3 a été trouvée dans [ref1].
- ligne 13 : le conteneur est lancé. [EJB3StandaloneBootstrap] est une classe du conteneur.
- ligne 16 : l'unité de déploiement configurée par [jboss-config.xml] est déployée dans le conteneur : gestionnaire JTA, source de données, pool de connexions, cache Hibernate, service JNDI sont mis en place.
- ligne 22 : on demande au conteneur de scanner le dossier bin du projet Eclipse pour y trouver les Ejb. Les Ejb des couches [service] et [dao] vont être trouvées et gérées par le conteneur.
- ligne 25 : un contexte JNDI est initialisé. Il va nous servir à localiser les Ejb.
- ligne 28 : l'Ejb correspondant à la classe [Service] de la couche [service] est demandé au service JNDI. Un Ejb peut être accédé localement (local) ou via le réseau (remote). Ici le nom "Service/local" de l'Ejb cherché désigne la classe [Service] de la couche [service] pour un accès local.
- maintenant, l'application est déployée et on détient une référence sur la couche [service]. On est dans la même situation qu'après la ligne 11 ci-dessous du code [InitDB] de la version Spring. On retrouve alors le même code dans les deux versions.
- ligne 36 (Jboss Ejb3) : on arrête le conteneur Ejb3.
L'exécution de [InitDB] donne les résultats suivants :
Le lecteur est invité à lire ces logs. On y trouve des informations intéressantes sur ce que fait le conteneur Ejb3.
IV-B-7. Tests unitaires [TestNG]▲
Le code du programme [TestNG] est le suivant :
- la méthode init (lignes 10-37) qui sert à mettre en place l'environnement nécessaire aux tests reprend le code expliqué précédemment dans [InitDB].
- la méthode terminate (lignes 40-45) qui est exécutée à la fin des tests (présence de l'annotation @AfterClass) arrête le conteneur Ejb3 (ligne 44).
- tout le reste est identique à ce qu'il était dans la version Spring.
Les tests réussissent :
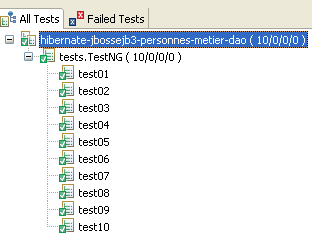
IV-B-8. Changer de SGBD▲

Pour changer de SGBD, il suffit de remplacer le contenu du dossier [META-INF] [2] par celui du dossier du SGBD dans le dossier [conf] [1]. Prenons l'exemple de SQL Server :
Le fichier [persistence.xml] est le suivant :
Seule une ligne a changé :
- ligne 24 : le dialecte SQL qu'Hibernate doit utiliser
Le fichier [jboss-config.xml] de SQL Server est lui, le suivant :
Seules les lignes 12-15 ont été changées : elles donnent les caractéristiques de la nouvelle connexion Jdbc.
Le lecteur est invité à répéter avec d'autres SGBD les tests décrits pour MySQL5.
IV-B-9. Changer d'implémentation JPA▲
Comme il a été indiqué plus haut, nous n'avons pas trouvé d'exemple d'utilisation du conteneur Jboss Ejb3 avec Toplink. A ce jour (juin 2007), je ne sais toujours pas si cette configuration est possible.
IV-C. Autres exemples▲
Résumons ce qui a été fait avec l'entité Personne. Nous avons construit trois architectures pour conduire les mêmes tests :
1 - une implémentation Spring / Hibernate
2 - une implémentation Spring / Toplink

3 - une implémentation Jboss Ejb3 / Hibernate

Les exemples du tutoriel reprennent ces trois architectures avec d'autres entités étudiées dans la première partie du tutoriel :
Categorie - Article

- en [1] : la version Spring / Hibernate
- en [2] : la version Spring / Toplink
- en [3] : la version Jboss Ejb3 / Hibernate
Personne- Adresse - Activite

- en [1] : la version Spring / Hibernate
- en [2] : la version Spring / Toplink
- en [3] : la version Jboss Ejb3 / Hibernate
Ces exemples n'amènent pas de nouveautés quant à l'architecture. Ils se placent simplement dans un contexte où il y a plusieurs entités à gérer avec des relations un-à-plusieurs ou plusieurs-à-plusieurs entre elles, ce que n'avaient pas les exemples avec l'entité Personne.
IV-D. Exemple 3 : Spring / JPA dans une application web▲
IV-D-1. Présentation▲
Nous reprenons ici une application présentée dans le document suivant :
[ref4] : Les bases du développement web MVC en Java [http://tahe.developpez.com/java/baseswebmvc/].
Ce document présente les bases du développement web MVC en Java. Pour comprendre l'exemple qui suit, le lecteur doit avoir ces bases. L'application web utilisera le serveur Tomcat. L'installation de celui-ci et son utilisation au sein d'Eclipse sont présentées au paragraphe , page .
L'application avait été développée avec une couche [dao] s'appuyant sur l'outil Ibatis / SqlMap [http://ibatis.apache.org/] qui assurait le pont relationnel / objet. Nous nous contentons de remplacer Ibatis par JPA. L'architecture de l'application sera la suivante :

L'application web que nous allons écrire va permettre de gérer un groupe de personnes avec quatre opérations :
- liste des personnes du groupe
- ajout d'une personne au groupe
- modification d'une personne du groupe
- suppression d'une personne du groupe
On reconnaîtra les quatre opérations de base sur une table de base de données. Les qui suivent montrent les pages que l'application échange avec l'utilisateur.
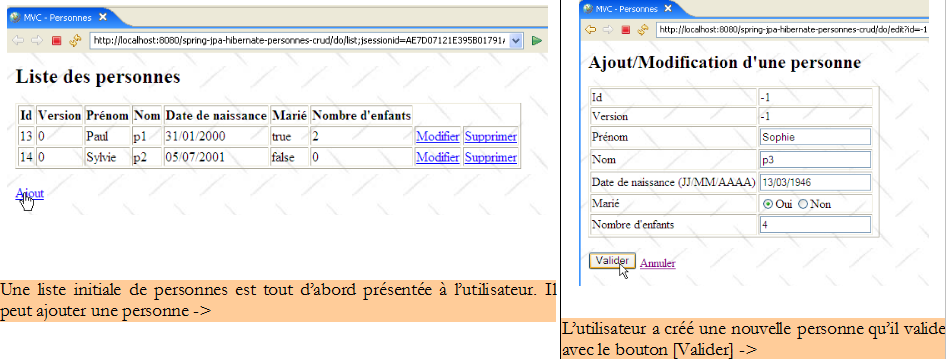
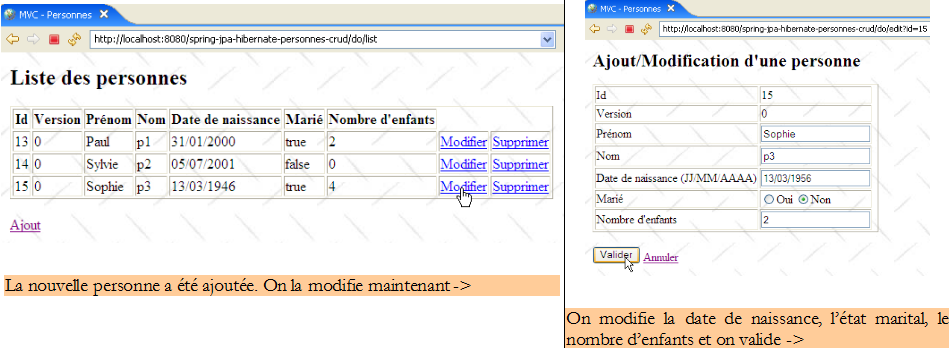
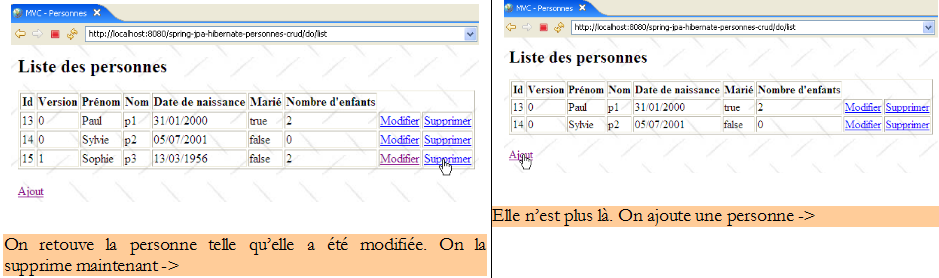
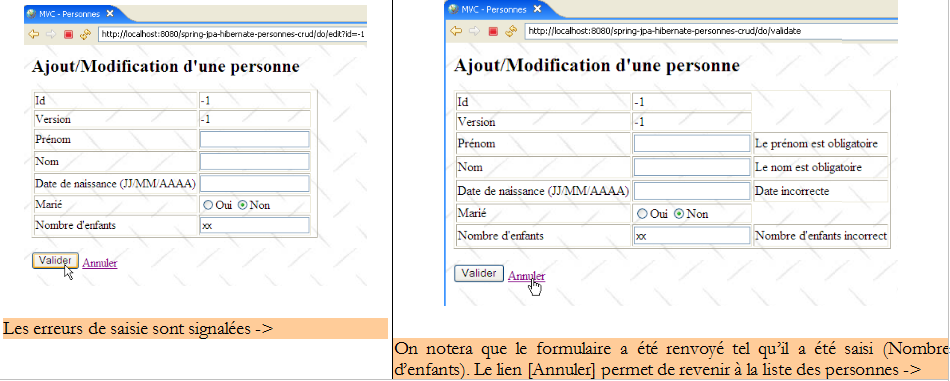
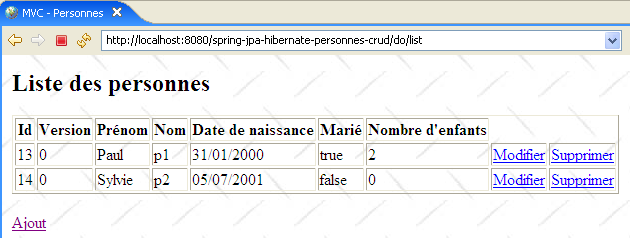
|
IV-D-2. Le projet Eclipse▲
Le projet Eclipse de l'application est le suivant :
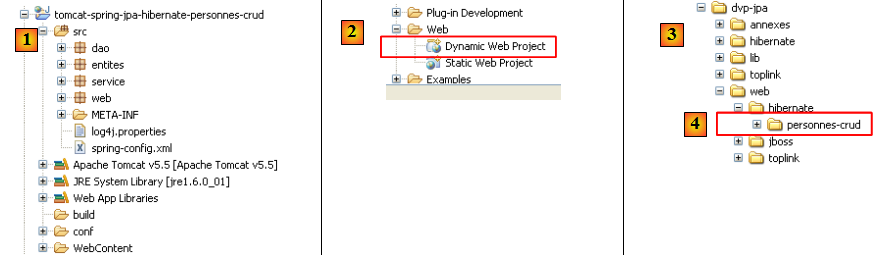
- en [1] : le projet web. C'est un projet Eclipse de type [Dynamic Web Project] [2]. On le trouvera en [4] dans le dossier [3] des exemples du tutoriel. On l'importera.
- en [5] : les sources et la configuration des couches [service, dao, jpa]. Nous conservons l'acquis [dao, entites, service] du projet Eclipse [hibernate-spring-personnes-metier-dao] étudié au paragraphe , page . Nous ne développons que la couche [web] représentée ici par le paquetage [web]. Par ailleurs nous conservons les fichiers de configuration [persistence.xml, spring-config.xml] de ce projet au détail près que nous allons utiliser le SGBD Postgres, ce qui se traduit par les modifications suivantes dans [spring-config.xml] :
Les lignes 8 et 16-19 ont été adaptées à Postgres.
- en [6] : le dossier [WebContent] contient les pages JSP du projet ainsi que les bibliothèques nécessaires. Ces dernières sont présentées en [8]
- l'application est utilisable avec divers SGBD. Il suffit de changer le fichier [spring-config.xml]. Le dossier [conf] [7] contient le fichier [spring-config.xml] adapté à divers SGBD.
IV-D-3. La couche [web]▲
Notre application a l'architecture multicouches suivante :
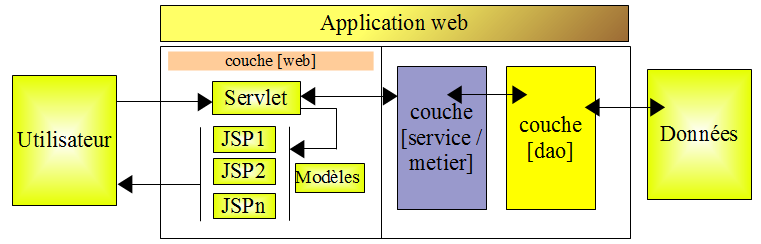
La couche [web] va offrir des écrans à l'utilisateur pour lui permettre de gérer le groupe de personnes :
- liste des personnes du groupe
- ajout d'une personne au groupe
- modification d'une personne du groupe
- suppression d'une personne du groupe
Pour cela, elle va s'appuyer sur la couche [service] qui elle même fera appel à la couche [dao]. Nous avons déjà présenté les écrans gérés par la couche [web] (page ). Pour décrire la couche web, nous allons présenter successivement :
- sa configuration
- ses vues
- son contrôleur
- quelques tests
IV-D-3-a. Configuration de l'application web▲
Revenons sur l'architecture du projet Eclipse :
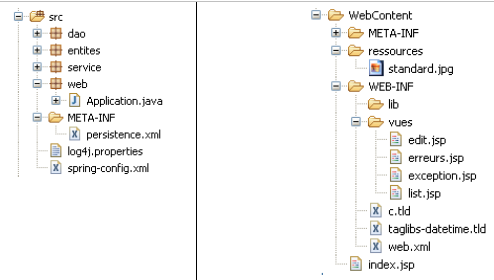
- dans le paquetage [web], on trouve le contrôleur de l'application web : la classe [Application].
- les pages JSP / JSTL de l'application sont dans [WEB-INF/vues].
- le dossier [WEB-INF/lib] contient les archives tierces nécessaires à l'application. Elles sont visibles dans le dossier [Web App Libraries].
[web.xml]
Le fichier [web.xml] est le fichier exploité par le serveur web pour charger l'application. Son contenu est le suivant :
- lignes 23-26 : les url [/do/*] seront traitées par la servlet [personnes]
- lignes 7-8 : la servlet [personnes] est une instance de la classe [Application], une classe que nous allons construire.
- lignes 9-20 : définissent trois paramètres [urlList, urlEdit, urlErreurs] identifiant les Url des pages JSP des vues [list, edit, erreurs].
- lignes 28-30 : l'application a une page d'entrée par défaut [index.jsp] qui se trouve à la racine du dossier de l'application web.
- lignes 32-35 : l'application a une page d'erreurs par défaut qui est affichée lorsque le serveur web récupère une exception non gérée par l'application.
- ligne 37 : la balise <exception-type> indique le type d'exception gérée par la directive <error-page>, ici le type [java.lang.Exception] et dérivé, donc toutes les exceptions.
- ligne 38 : la balise <location> indique la page JSP à afficher lorsqu'une exception du type défini par <exception-type> se produit. L'exception e survenue est disponible à cette page dans un objet nommé exception si la page a la directive :
- si <exception-type> précise un type T1 et qu'une exception de type T2 non dérivé de T1 remonte jusqu'au serveur web, celui-ci envoie au client une page d'exception propriétaire généralement peu conviviale. D'où l'intérêt de la balise <error-page> dans le fichier [web.xml].
[index.jsp]
Cette page est présentée si un utilisateur demande directement le contexte de l'application sans préciser d'url, c.a.d. ici [/spring-jpa-hibernate-personnes-crud]. Son contenu est le suivant :
[index.jsp] redirige (ligne 4) le client vers l'url [/do/list]. Cette url affiche la liste des personnes du groupe.
IV-D-3-b. Les pages JSP / JSTL de l'application▲
La vue []
Elle sert à afficher la liste des personnes :
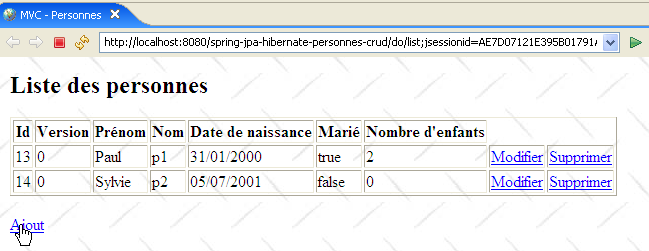
Son code est le suivant :
- cette vue reçoit deux éléments dans son modèle :
- l'élément [personnes] associé à un objet de type [List] d'objets de type [Personne] : une liste de personnes.
- l'élément facultatif [erreurs] associé à un objet de type [List] d'objets de type [String] : une liste de messages d'erreur.
- lignes 31-43 : on parcourt la liste ${personnes} pour afficher un tableau HTML contenant les personnes du groupe.
- ligne 40 : l'url pointée par le lien [Modifier] est paramétrée par le champ [id] de la personne courante afin que le contrôleur associé à l'url [/do/edit] sache quelle est la personne à modifier.
- ligne 41 : il est fait de même pour le lien [Supprimer].
- ligne 37 : pour afficher la date de naissance de la personne sous la forme JJ/MM/AAAA, on utilise la balise <dt> de la bibliothèque de balise [DateTime] du projet Apache [Jakarta Taglibs] :

Le fichier de description de cette bibliothèque de balises est défini ligne 3.
- ligne 46 : le lien [Ajout] d'ajout d'une nouvelle personne a pour cible l'url [/do/edit] comme le lien [Modifier] de la ligne 40. C'est la valeur -1 du paramètre [id] qui indique qu'on a affaire à un ajout plutôt qu'une modification.
- lignes 10-18 : si l'élément ${erreurs} est dans le modèle, alors on affiche les messages d'erreurs qu'il contient.
La vue []
Elle sert à afficher le formulaire d'ajout d'une nouvelle personne ou de modification d'une personne existante :
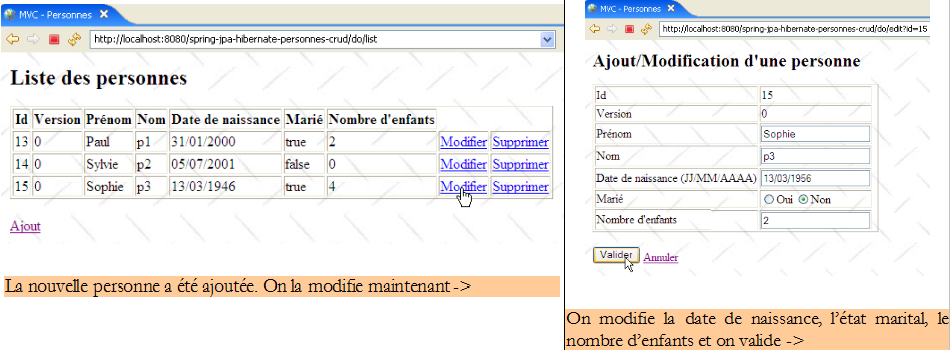
Le code de la vue [edit.jsp] est le suivant :
Cette vue présente un formulaire d'ajout d'une nouvelle personne ou de mise à jour d'une personne existante. Par la suite et pour simplifier l'écriture, nous utiliserons l'unique terme de [mise à jour]. Le bouton [Valider] (ligne 73) provoque le POST du formulaire à l'url [/do/validate] (ligne 16). Si le POST échoue, la vue [edit.jsp] est réaffichée avec la ou les erreurs qui se sont produites, sinon la vue [list.jsp] est affichée.
- la vue [edit.jsp] affichée aussi bien sur un GET que sur un POST qui échoue, reçoit les éléments suivants dans son modèle :
| attribut | GET | POST |
| id | identifiant de la personne mise à jour | idem |
| version | sa version | idem |
| prenom | son prénom | prénom saisi |
| nom | son nom | nom saisi |
| datenaissance | sa date de naissance | date de naissance saisie |
| marie | son état marital | état marital saisi |
| nbenfants | son nombre d'enfants | nombre d'enfants saisi |
| erreurEdit | vide | un message d'erreur signalant un échec de l'ajout ou de la modification au moment du POST provoqué par le bouton [Envoyer]. Vide si pas d'erreur. |
| erreurPrenom | vide | signale un prénom erroné - vide sinon |
| erreurNom | vide | signale un nom erroné - vide sinon |
| erreurDateNaissance | vide | signale une date de naissance erronée - vide sinon |
| erreurNbEnfants | vide | signale un nombre d'enfants erroné - vide sinon |
- lignes 11-15 : si le POST du formulaire se passe mal, on aura [erreurEdit!=''] et un message d'erreur sera affiché.
- ligne 16 : le formulaire sera posté à l'url [/do/validate]
La vue []
Elle sert à afficher une page signalant qu'il s'est produit une exception non gérée par l'application et qui est remontée jusqu'àu serveur web.
Par exemple, supprimons une personne qui n'existe pas dans le groupe :
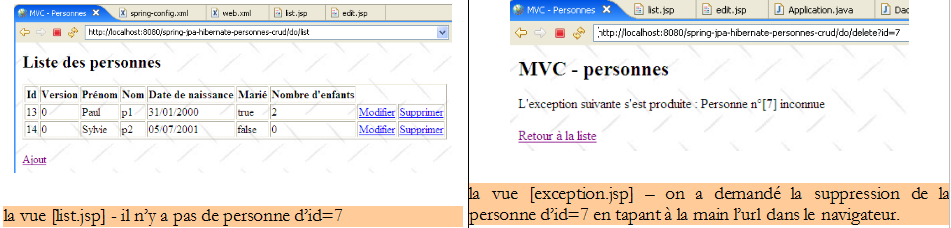
Le code de la vue [exception.jsp] est le suivant :
- cette vue reçoit une clé dans son modèle l'élément [exception] qui est l'exception qui a été interceptée par le serveur web. Pour que cet élément soit inclus dans le modèle de la page JSP par le serveur web, il faut que la page ait défini la balise de la ligne 3.
- ligne 6 : on fixe à 200 le code d'état HTTP de la réponse. C'est le premier entête HTTP de la réponse. Le code 200 signifie au client que sa demande a été honorée. Généralement un document HTML a été intégré dans la réponse du serveur. C'est le cas ici. Si on ne fixe pas à 200 le code d'état HTTP de la réponse, il aura ici la valeur 500 qui signifie qu'il s'est produit une erreur. En effet, le serveur web ayant intercepté une exception non gérée trouve cette situation anormale et le signale par le code 500. La réaction au code HTTP 500 diffère selon les navigateurs : Firefox affiche le document HTML qui peut accompagner cette réponse alors qu'IE ignore ce document et affiche sa propre page. C'est pour cette raison que nous avons remplacé le code 500 par le code 200.
- ligne 16 : le texte de l'exception est affiché
- ligne 18 : on propose à l'utilisateur un lien pour revenir à la liste des personnes
La vue []
Elle sert à afficher une page signalant les erreurs d'initialisation de l'application, c.a.d. les erreurs détectées lors de l'exécution de la méthode [init] de la servlet du contrôleur. Ce peut être par exemple l'absence d'un paramètre dans le fichier [web.xml] comme le montre l'exemple ci-dessous :
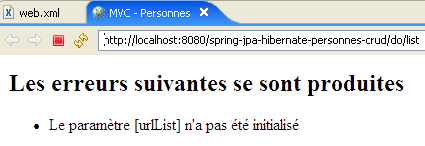
Le code de la page [erreurs.jsp] est le suivant :
La page reçoit dans son modèle un élément [erreurs] qui est un objet de type [ArrayList] d'objets [String], ces derniers étant des messages d'erreurs. Ils sont affichés par la boucle des lignes 13-15.
IV-D-3-c. Le contrôleur de l'application▲
Le contrôleur [Application] est défini dans le paquetage [web] :
Structure et initialisation du contrôleur
Le squelette du contrôleur [Application] est le suivant :
- lignes 21-34 : on récupère les paramètres attendus dans le fichier [web.xml].
- lignes 37-39 : le paramètre [urlErreurs] doit être obligatoirement présent car il désigne l'url de la vue [erreurs] capable d'afficher les éventuelles erreurs d'initialisation. S'il n'existe pas, on interrompt l'application en lançant une [ServletException] (ligne 39). Cette exception va remonter au serveur web et être gérée par la balise <error-page> du fichier [web.xml]. La vue [exception.jsp] est donc affichée :
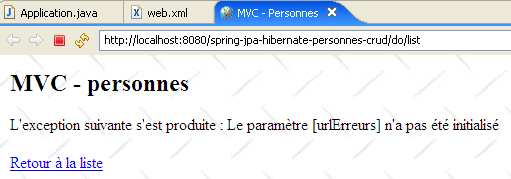
Le lien [Retour à la liste] ci-dessus est inopérant. L'utiliser redonne la même réponse tant que l'application n'a pas été modifiée et rechargée. Il est utile pour d'autres types d'exceptions comme nous l'avons déjà vu.
- lignes 40-43 : exploitent le fichier de configuration Spring pour récupérer une référence sur la couche [service]. Après l'initialisation du contrôleur, les méthodes de celui-ci disposent d'une référence [service] sur la couche [service] (ligne 15) qu'elles vont utiliser pour exécuter les actions demandées par l'utilisateur. Celles-ci vont être interceptées par la méthode [doGet] qui va les faire traiter par une méthode particulière du contrôleur :
| Url | Méthode HTTP | méthode contrôleur |
| /do/list | GET | doListPersonnes |
| /do/edit | GET | doEditPersonne |
| /do/validate | POST | doValidatePersonne |
| /do/delete | GET | doDeletePersonne |
La méthode [doGet]
Cette méthode a pour but d'orienter le traitement des actions demandées par l'utilisateur vers la bonne méthode. Son code est le suivant :
- lignes 7-13 : on vérifie que la liste des erreurs d'initialisation est vide. Si ce n'est pas le cas, on fait afficher la vue [erreurs(erreurs)] qui va signaler la ou les erreurs.
- ligne 15 : on récupère la méthode [get] ou [post] que le client a utilisée pour faire sa requête.
- ligne 17 : on récupère la valeur du paramètre [action] de la requête.
- lignes 23-27 : traitement de la requête [GET /do/list] qui demande la liste des personnes.
- lignes 28-32 : traitement de la requête [GET /do/delete] qui demande la suppression d'une personne.
- lignes 33-37 : traitement de la requête [GET /do/edit] qui demande le formulaire de mise à jour d'une personne.
- lignes 38-42 : traitement de la requête [POST /do/validate] qui demande la validation de la personne mise à jour.
- ligne 44 : si l'action demandée n'est pas l'une des cinq précédentes, alors on fait comme si c'était [GET /do/list].
La méthode [doListPersonnes]
Cette méthode traite la requête [GET /do/list] qui demande la liste des personnes :
Son code est le suivant :
- ligne 4 : on demande à la couche [service] la liste des personnes du groupe et on met celle-ci dans le modèle sous la clé " personnes ".
- ligne 6 : on fait afficher la vue [list.jsp] décrite page .
La méthode [doDeletePersonne]
Cette méthode traite la requête [GET /do/delete?id=XX] qui demande la suppression de la personne d'id=XX. L'url [/do/delete?id=XX] est celle des liens [Supprimer] de la vue [list.jsp] :
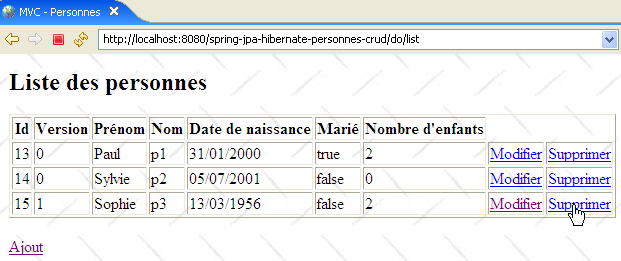
dont le code est le suivant :
Ligne 12, on voit l'url [/do/delete?id=XX] du lien [Supprimer]. La méthode [doDeletePersonne] qui doit traiter cette url doit supprimer la personne d'id=XX puis faire afficher la nouvelle liste des personnes du groupe. Son code est le suivant :
- ligne 4 : l'url traitée est de la forme [/do/delete?id=XX]. On récupère la valeur [XX] du paramètre [id].
- ligne 6 : on demande à la couche [service] la suppression de la personne ayant l'id obtenu. Nous ne faisons aucune vérification. Si la personne qu'on cherche à supprimer n'existe pas, la couche [dao] lance une exception que laisse remonter la couche [service]. Nous ne la gérons pas non plus ici, dans le contrôleur. Elle remontera donc jusqu'au serveur web qui par configuration fera afficher la page [exception.jsp], décrite page :
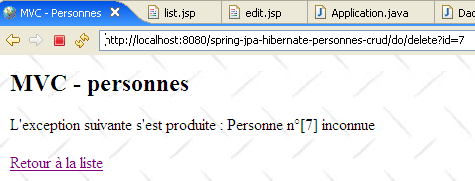
- ligne 9 : si la suppression a eu lieu (pas d'exception), on demande au client de se rediriger vers l'Url relative [list]. Comme celle qui vient d'être traitée est [/do/delete], l'Url de redirection sera [/do/list]. Le navigateur sera donc amené à faire un [GET /do/list] qui provoquera l'affichage de la liste des personnes.
La méthode [doEditPersonne]
Cette méthode traite la requête [GET /do/edit?id=XX] qui demande le formulaire de mise à jour de la personne d'id=XX. L'url [/do/edit?id=XX] est celle des liens [Modifier] et celui du lien [Ajout] de la vue [list.jsp] :
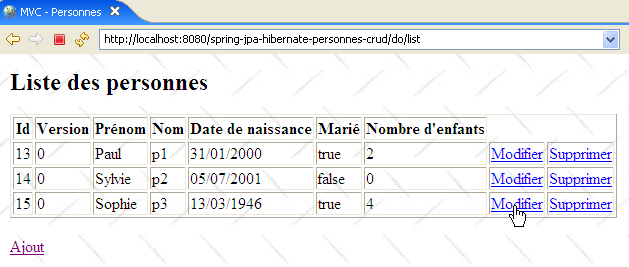
dont le code est le suivant :
Ligne 11, on voit l'url [/do/edit?id=XX] du lien [Modifier] et ligne 17, l'url [/do/edit?id=-1] du lien [Ajout]. La méthode [doEditPersonne] doit faire afficher le formulaire d'édition de la personne d'id=XX ou s'il s'agit d'un ajout présenter un formulaire vide.
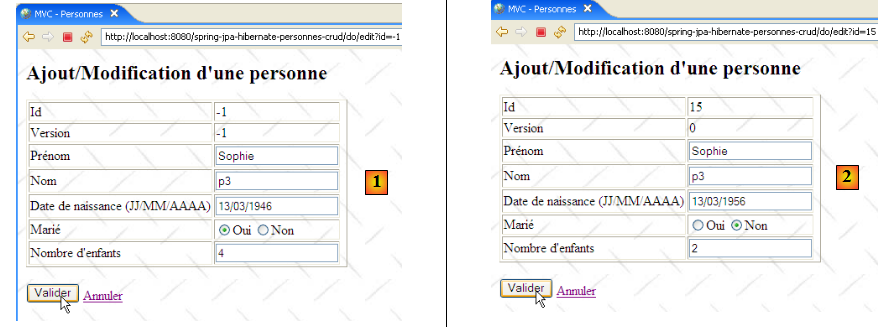
- en [1] ci-dessus, le formulaire d'ajout et en [2] le formulaire de modification.
Le code de la méthode [doEditPersonne] est le suivant :
- le GET a pour cible une url du type [/do/edit?id=XX]. Ligne 4, nous récupérons la valeur de [id]. Ensuite il y a deux cas :
- id est différent de -1. Alors il s'agit d'une modification et il faut afficher un formulaire prérempli avec les informations de la personne à modifier. Ligne 9, cette personne est demandée à la couche [service].
- id est égal à -1. Alors il s'agit d'un ajout et il faut afficher un formulaire vide. Pour cela, une personne vide est créée ligne 14.
- dans les deux cas, les éléments [id, version] du modèle de la page [edit.jsp] décrite page sont initialisés.
- l'objet [Personne] obtenu est placé dans le modèle de la page [edit.jsp]. Ce modèle comprend les éléments suivants [erreurEdit, id, version, prenom, erreurPrenom, nom, erreurNom, datenaissance, erreurDateNaissance, marie, nbenfants, erreurNbEnfants]. Ces éléments sont initialisés lignes 19-31 à l'exception de ceux dont la valeur est la chaîne vide [erreurPrenom, erreurNom, erreurDateNaissance, erreurNbEnfants]. On sait qu'en leur absence dans le modèle, la bibliothèque JSTL affichera une chaîne vide pour leur valeur. Bien que l'élément [erreurEdit] ait également pour valeur une chaîne vide, il est néanmoins initialisé car un test est fait sur sa valeur dans la page [edit.jsp].
- une fois le modèle prêt, le contrôle est passé à la page [edit.jsp], ligne 33, qui va générer la vue [edit].
La méthode [doValidatePersonne]
Cette méthode traite la requête [POST /do/validate] qui valide le formulaire de mise à jour. Ce POST est déclenché par le bouton [Valider] :
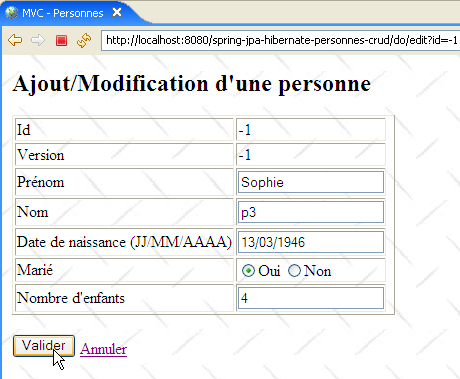
Rappelons les éléments de saisie du formulaire HTML de la vue ci-dessus :
La requête POST contient les paramètres [prenom, nom, datenaissance, marie, nbenfants, id] et est postée à l'url [/do/validate] (ligne 1). Elle est traitée par la méthode [doValidatePersonne] suivante :
- lignes 7-13 : le paramètre [prenom] de la requête POST est récupéré et sa validité vérifiée. S'il s'avère incorrect, l'élément [erreurPrenom] est initialisé avec un message d'erreur et placé dans les attributs de la requête.
- lignes 15-21 : on opère de façon similaire pour le paramètre [nom]
- lignes 23-30 : on opère de façon similaire pour le paramètre [datenaissance]
- ligne 32 : on récupère le paramètre [marie]. On ne fait pas de vérification sur sa validité parce qu'à priori il provient de la valeur d'un bouton radio. Ceci dit, rien n'empêche un programme de faire un [POST /…/do/validate] accompagné d'un paramètre [marie] fantaisiste. Nous devrions donc tester la validité de ce paramètre. Ici, on se repose sur notre gestion des exceptions qui provoquent l'affichage de la page [exception.jsp] si le contrôleur ne les gère pas lui-même. Si donc, la conversion du paramètre [marie] en booléen échoue ligne 32, une exception en sortira qui aboutira à l'envoi de la page [exception.jsp] au client. Ce fonctionnement nous convient.
- lignes 34-50 : on récupère le paramètre [nbenfants] et on vérifie sa valeur.
- ligne 52 : on récupère le paramètre [id] sans vérifier sa valeur
- lignes 54-59 : si le formulaire est erroné, il est réaffiché avec les messages d'erreurs construits précédemment
- lignes 62-67 : s'il est valide, on construit un nouvel objet [Personne] avec les éléments du formulaire
- lignes 69-82 : la personne est sauvegardée. La sauvegarde peut échouer. Dans un cadre multiutilisateurs, la personne à modifier a pu être supprimée ou bien déjà modifiée par quelqu'un d'autre. Dans ce cas, la couche [dao] va lancer une exception qu'on gère ici.
- ligne 84 : s'il n'y a pas eu d'exception, on redirige le client vers l'url [/do/list] pour lui présenter le nouvel état du groupe.
- ligne 79 : s'il y a eu exception lors de la sauvegarde, on redemande le réaffichage du formulaire initial en lui passant le message d'erreur de l'exception (3ième paramètre).
La méthode [showFormulaire] (lignes 88-97) construit le modèle nécessaire à la page [edit.jsp] avec les valeurs saisies (request.getParameter(" … ")). On se rappelle que les messages d'erreurs ont déjà été placés dans le modèle par la méthode [doValidatePersonne]. La page [edit.jsp] est affichée ligne 99.
IV-D-4. Les tests de l'application web▲
Un certain nombre de tests ont été présentés au paragraphe , page . Nous invitons le lecteur à les rejouer. Nous montrons ici d'autres copies d'écran qui illustrent les cas de conflits d'accès aux données dans un cadre multiutilisateurs :
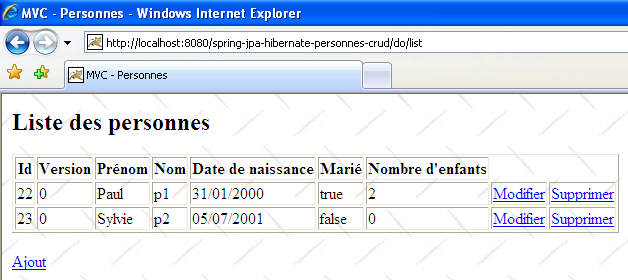
[Firefox] sera le navigateur de l'utilisateur U1. Celui-ci demande l'url [http://localhost:8080/spring-jpa-hibernate-personnes-crud/do/list] :
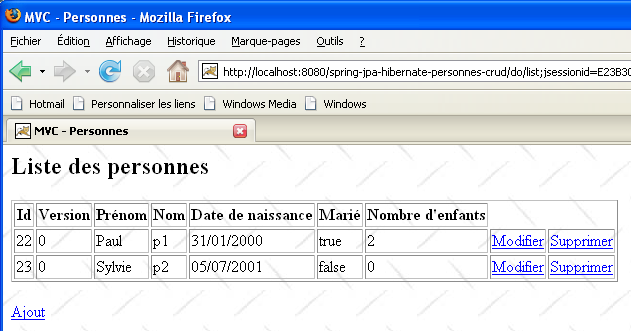
[IE7] sera le navigateur de l'utilisateur U2. Celui-ci demande la même Url :
L'utilisateur U1 entre en modification de la personne [p2] :
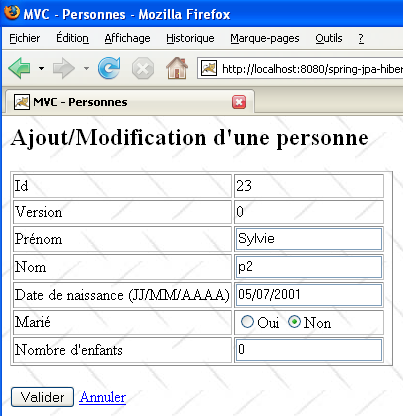
L'utilisateur U2 fait de même :
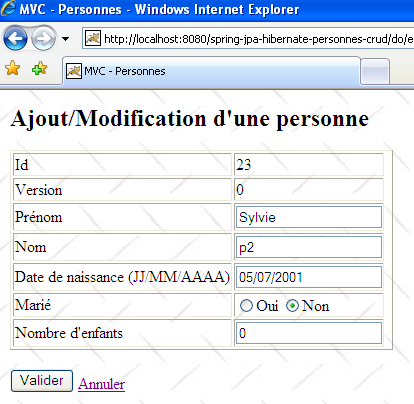
L'utilisateur U1 fait des modifications et valide :
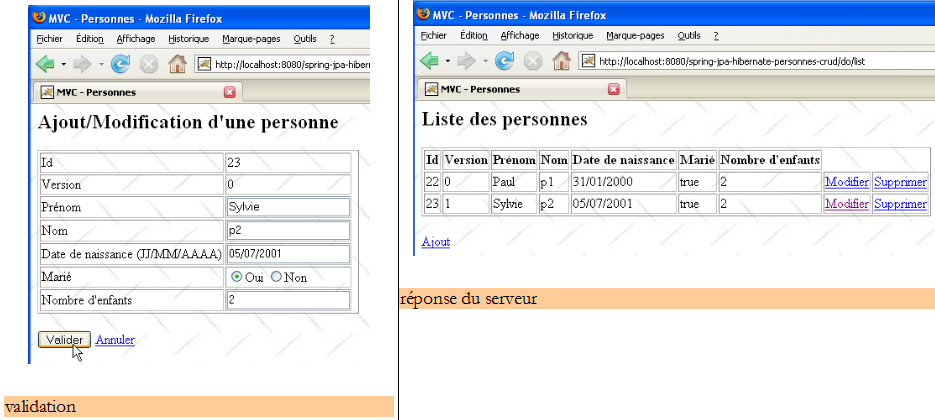
L'utilisateur U2 fait de même :
L'utilisateur U2 revient à la liste des personnes avec le lien [Retour à la liste] du formulaire :
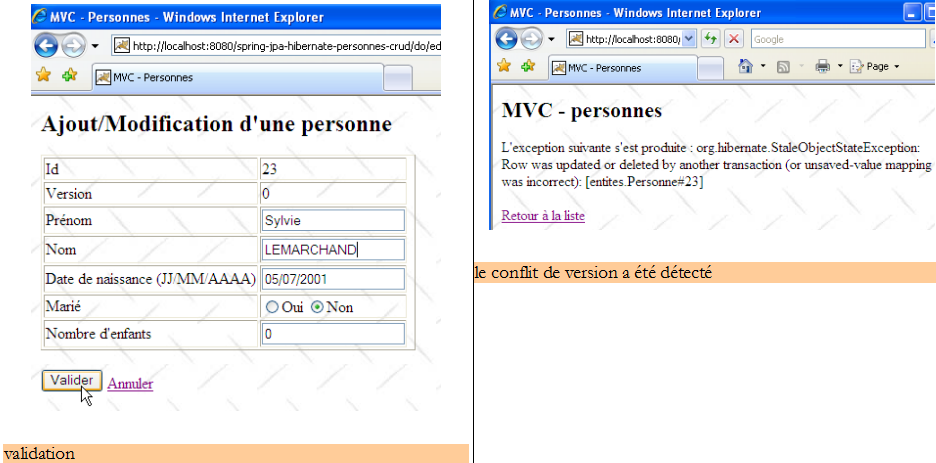
Il trouve la personne [Lemarchand] telle que U1 l'a modifiée (mariée, 2 enfants). Le n° de version de p2 a changé. Maintenant U2 supprime [p2] :
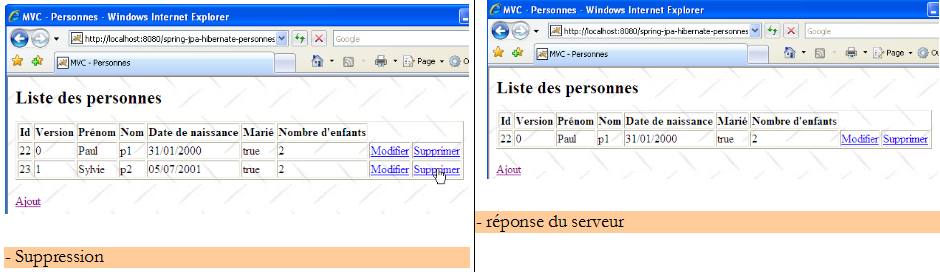
U1 a toujours sa propre liste et veut modifier [p2] de nouveau :
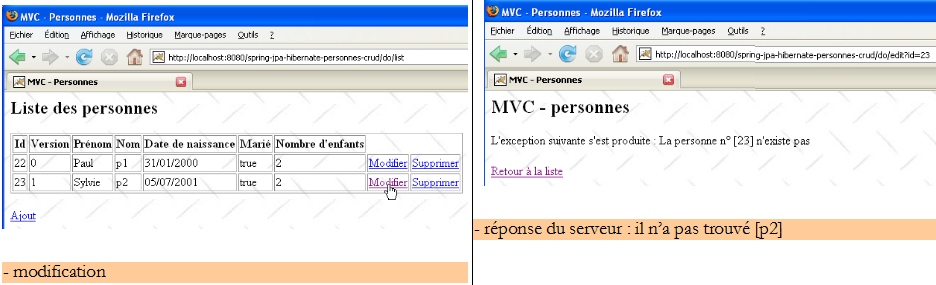
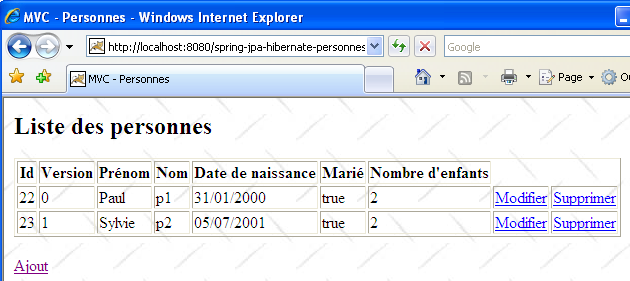
U1 utilise le lien [Retour à la liste] pour voir de quoi il retourne :
Il découvre qu'effectivement [p2] ne fait plus partie de la liste…
IV-D-5. Version 2▲
Nous modifions légèrement la version précédente pour utiliser les archives des couches [service, dao, jpa] et non plus leurs codes source :

- en [1] : le nouveau projet Eclipse. On notera la disparition des paquetages [service, dao, entites]. Ceux-ci ont été encapsulés dans l'archive [service-dao-jpa-personne.jar] [2] placée dans [WEB-INF/lib].
- le dossier du projet est en [4]. On l'importera.
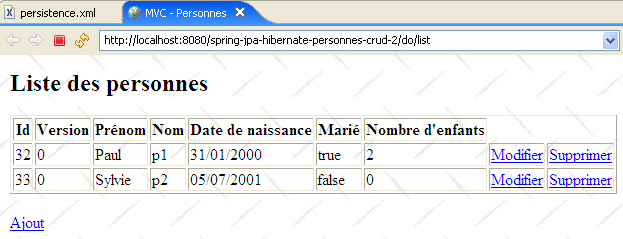
Il n'y a rien de plus à faire. Lorsque la nouvelle application web est lancée et qu'on demande la liste des personnes, on reçoit la réponse suivante :
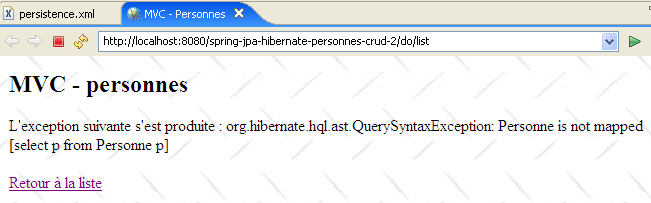
|
Hibernate ne trouve pas l'entité [Personne]. Pour résoudre ce problème, on est obligés de déclarer explicitement dans [persistence.xml] les entités gérées :
- ligne 7 : l'entité Personne est déclarée.
Ceci fait, l'exception disparaît :
|
IV-D-6. Changer d'implémentation JPA▲
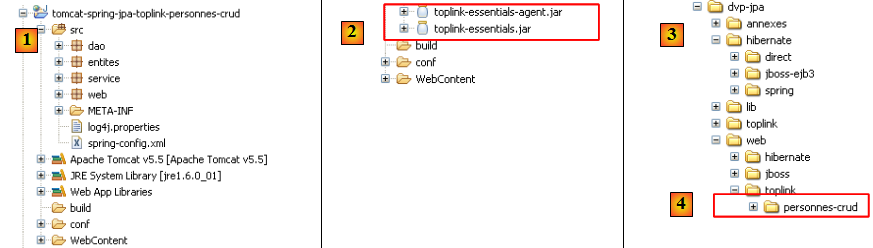
- en [1] : le nouveau projet Eclipse
- en [2] : les bibliothèques Toplink ont remplacé les bibliothèques Hibernate
- le dossier du projet est en [4]. On l'importera.
Changer d'implémentation JPA n'implique que quelques changements dans le fichier [spring-config.xml]. Rien d'autre ne change. Les changements amenés dans le fichier [spring-config.xml] ont été expliqués au paragraphe , page :
Peu de lignes doivent être changées pour passer d'Hibernate à Toplink :
- ligne 11 : l'implémentation JPA est désormais faite par Toplink
- ligne 13 : la propriété [databasePlatform] a une autre valeur qu'avec Hibernate : le nom d'une classe propre à Toplink. Où trouver ce nom a été expliqué au paragraphe , page .
C'est tout. On notera la facilité avec laquelle on peut changer de SGBD ou d'implémentation JPA avec Spring. On n'a quand même pas tout a fait fini. Lorsqu'on exécute l'application, on a une exception :
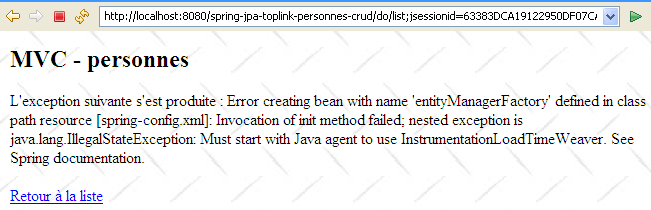
|
On reconnaîtra là un problème rencontré et décrit au paragraphe , page . Il est résolu en lançant la JVM avec un agent Spring. Pour cela, on modifie la configuration de lancement de Tomcat :
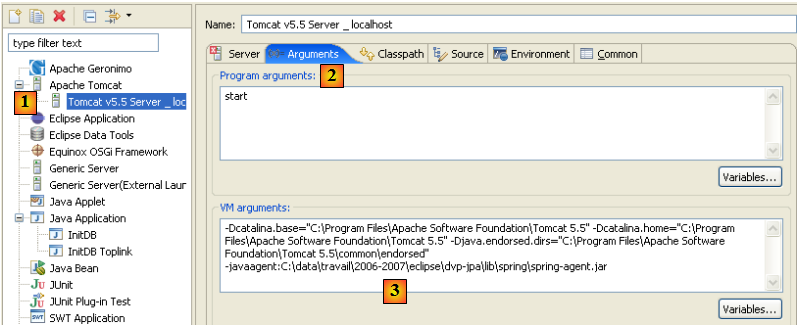
- en [1] : on a pris l'option [Run / Run…] pour modifier la configuration de Tomcat
- en [2] : on a sélectionné l'onglet [Arguments]
- en [3] : on a rajouté le paramètre -javaagent tel qu'il a été décrit au paragraphe , page .
Ceci fait, on peut demander la liste des personnes :
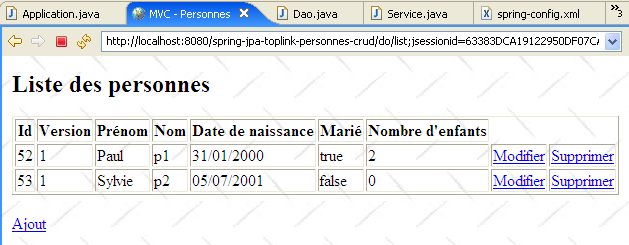
IV-E. Autres exemples▲
Nous aurions voulu montrer un exemple web où le conteneur Spring était remplacé par le conteneur Jboss Ejb3 étudié au paragraphe , page :
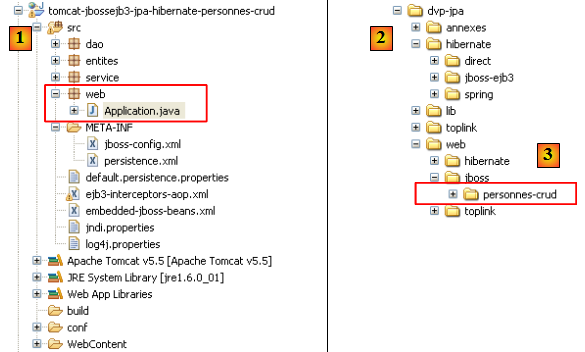
- en [1] : le projet Eclipse
- en [3] : son emplacement dans le dossier des exemples. On l'importera.
Nous avons repris la configuration [jboss-config.xml, persistence.xml] décrite au paragraphe , page , puis avons modifié la méthode [init] du contrôleur [Application.java] de la façon suivante :
- lignes 28-38 : on démarre le conteneur Ejb3. Celui-ci remplace le conteneur Spring.
- ligne 41 : on demande une référence sur la couche [service] de l'application.
A priori, ce sont les seules modifications à apporter. A l'exécution, on a l'erreur suivante :
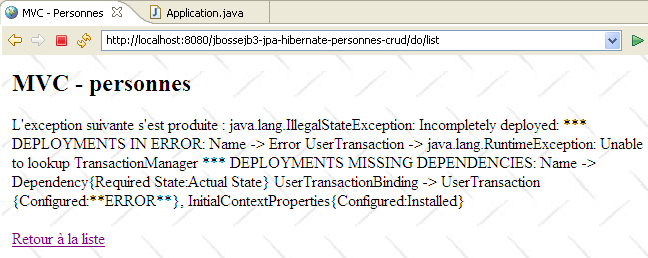
|
Je n'ai pas été capable de comprendre où était exactement le problème. L'exception rapportée par Tomcat semble dire que l'objet nommé "TransactionManager" a été demandé au service JNDI et que celui-ci ne le connaissait pas. Je laisse aux lecteurs le soin d'apporter une solution à ce problème. Si une solution est trouvée, elle sera intégrée au document.