


XVIII. Etude de cas : Struts 2 / Tiles / Spring / Hibernate / MySQL▲
Nous allons terminer notre apprentissage de Struts par une étude de cas. Afin d'être réaliste, l'exemple étudié va être nettement plus complexe que ceux étudiés précédemment. Pour les débutants, il est sans doute préférable d'approfondir les bases de Struts 2 avec des applications personnelles avant d'aborder cette étude de cas.
L'application va utiliser une architecture à couches :

L'ensemble des couches [metier], [dao], [jpa/hibernate] nous sera fourni sous la forme d'une archive jar dont nous détaillerons les fonctionnalités. L'intégration des couches sera assurée par Spring. La couche [web] sera implémentée par Struts 2.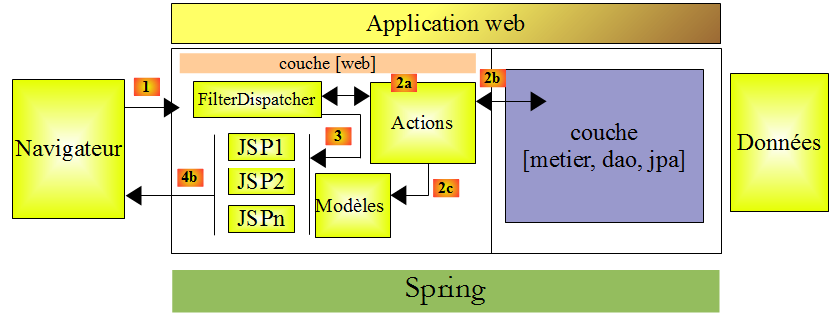
XVIII-A. Le problème▲
On se propose d'écrire une application web permettant d'établir le bulletin de salaire des assistantes maternelles employées par la "Maison de la petite enfance" d'une commune.
Cette étude de cas est présentée dans le document :
Introduction à Java EE 5 disponible à l'Url [http://tahe.developpez.com/java/javaee]
Dans ce document, l'étude de cas est implémentée avec l'architecture multi-couches suivante :

La couche [web] est implémentée à l'aide du framework JSF (Java Server Faces). Nous allons prendre cette même architecture en implémentant la couche [web] avec Struts 2. Pour montrer l'intérêt des architectures en couches, nous allons utiliser l'archive jar des couches [metier, dao, jpa] de la version JSF et la connecter à une couche [web / struts2] :
Nous présenterons les éléments suivants des couches [metier, dao, jpa] :
- la couche [web] s'adresse à l'interface de la couche [métier]. Nous présenterons cette interface.
- la couche [jpa] accède à une base de données. Nous la présenterons.
- la couche [jpa] transforme les lignes des tables de la base de données en entités Jpa manipulées par toutes les couches de l'application. Nous les présenterons.
- les couches [metier, dao, jpa] sont instanciées par Spring. Nous présenterons le fichier de configuration qui réalise cette instanciation et cette intégration.
XVIII-B. La base de données▲
Nous utiliserons la base de données MySQL [dbpam_hibernate] suivante :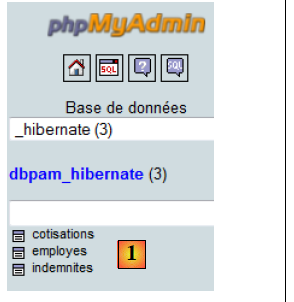
- en [1], la base a trois tables :
- [employes] : une table qui enregistre les employées d'une crèche
- [cotisations] : une table qui enregistre des taux de cotisations sociales
- [indemnites] : une table qui enregistre des informations permettant de calculer la paie des employées
Table [employes] 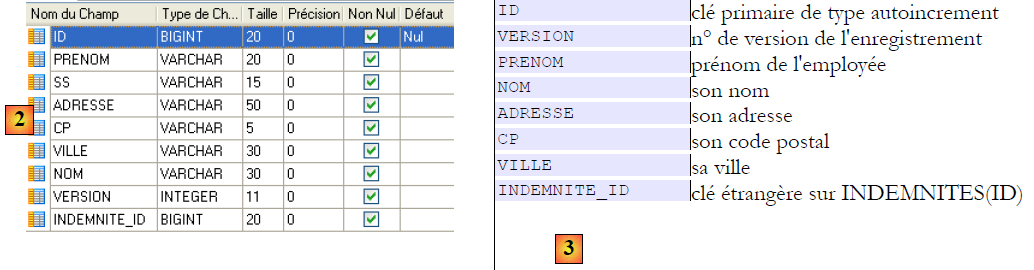
- en [2], la table des employés et en [3], la signification de ses champs
Le contenu de la table pourrait être le suivant :
Table [cotisations] 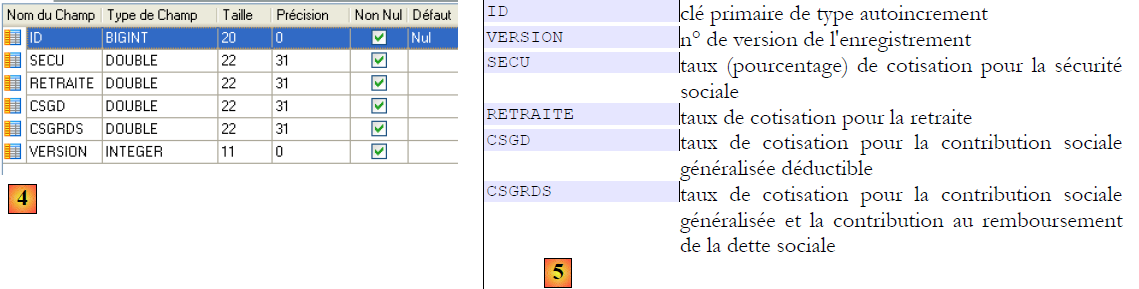
- en [4], la table des cotisations et en [5], la signification de ses champs
Le contenu de la table pourrait être le suivant :![]()
Table [indemnites] 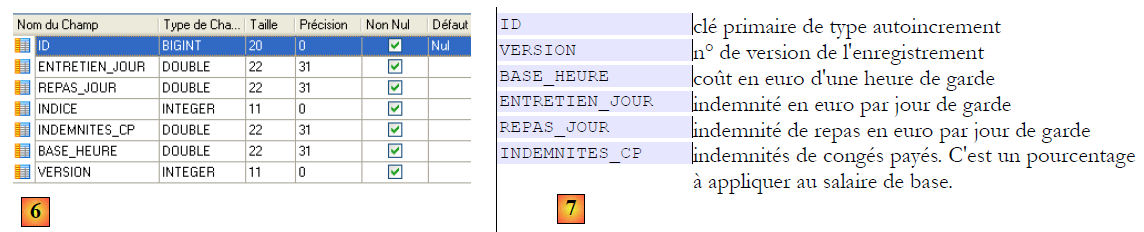
- en [6], la table des indemnités et en [7], la signification de ses champs
Le contenu de la table pourrait être le suivant :
L'exportation de la structure de la base vers un fichier SQL donne le résultat suivant :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
#
# Structure for the `cotisations` table :
#
CREATE TABLE `cotisations` (
`ID` bigint(20) NOT NULL auto_increment,
`SECU` double NOT NULL,
`RETRAITE` double NOT NULL,
`CSGD` double NOT NULL,
`CSGRDS` double NOT NULL,
`VERSION` int(11) NOT NULL,
PRIMARY KEY (`ID`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=latin1;
#
# Structure for the `indemnites` table :
#
CREATE TABLE `indemnites` (
`ID` bigint(20) NOT NULL auto_increment,
`ENTRETIEN_JOUR` double NOT NULL,
`REPAS_JOUR` double NOT NULL,
`INDICE` int(11) NOT NULL,
`INDEMNITES_CP` double NOT NULL,
`BASE_HEURE` double NOT NULL,
`VERSION` int(11) NOT NULL,
PRIMARY KEY (`ID`),
UNIQUE KEY `INDICE` (`INDICE`)
) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=latin1;
#
# Structure for the `employes` table :
#
CREATE TABLE `employes` (
`ID` bigint(20) NOT NULL auto_increment,
`PRENOM` varchar(20) NOT NULL,
`SS` varchar(15) NOT NULL,
`ADRESSE` varchar(50) NOT NULL,
`CP` varchar(5) NOT NULL,
`VILLE` varchar(30) NOT NULL,
`NOM` varchar(30) NOT NULL,
`VERSION` int(11) NOT NULL,
`INDEMNITE_ID` bigint(20) NOT NULL,
PRIMARY KEY (`ID`),
UNIQUE KEY `SS` (`SS`),
KEY `FK_EMPLOYES_INDEMNITE_ID` (`INDEMNITE_ID`),
CONSTRAINT `FK_EMPLOYES_INDEMNITE_ID` FOREIGN KEY (`INDEMNITE_ID`) REFERENCES `indemnites` (`ID`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=latin1;
XVIII-C. Les entités Jpa▲
Dans l'architecture suivante 
La couche [Jpa] joue le rôle de pont entre les objets manipulés par la couche [dao] et les lignes des tables de la base de données manipulées par le pilote Jdbc. Les lignes des tables lues dans la base de données sont transformées en objets appelées entités Jpa. Inversement en écriture, les entités Jpa sont transformées en lignes dans les tables. Ces entités sont manipulées par toutes les couches et notamment par la couche web. Il nous faut donc les connaître :
L'entité [Employe] représente une ligne de la table [Employes]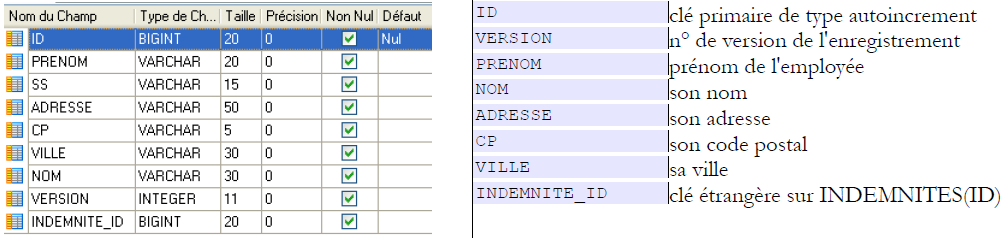
L'entité [Employe] est la suivante :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
52.
53.
54.
55.
56.
57.
58.
59.
60.
61.
package jpa;
...
@Entity
@Table(name="EMPLOYES")
public class Employe implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Version
@Column(name="VERSION",nullable=false)
private int version;
@Column(name="SS", nullable=false, unique=true, length=15)
private String SS;
@Column(name="NOM", nullable=false, length=30)
private String nom;
@Column(name="PRENOM", nullable=false, length=20)
private String prenom;
@Column(name="ADRESSE", nullable=false, length=50)
private String adresse;
@Column(name="VILLE", nullable=false, length=30)
private String ville;
@Column(name="CP", nullable=false, length=5)
private String codePostal;
@ManyToOne
@JoinColumn(name="INDEMNITE_ID",nullable=false)
private Indemnite indemnite;
public Employe() {
}
public Employe(String SS, String nom, String prenom, String adresse, String ville, String codePostal, Indemnite indemnite){
setSS(SS);
setNom(nom);
setPrenom(prenom);
setAdresse(adresse);
setVille(ville);
setCodePostal(codePostal);
setIndemnite(indemnite);
}
@Override
public String toString() {
return "jpa.Employe[id=" + getId()
+ ",version="+getVersion()
+",SS="+getSS()
+ ",nom="+getNom()
+ ",prenom="+getPrenom()
+ ",adresse="+getAdresse()
+",ville="+getVille()
+",code postal="+getCodePostal()
+",indice="+getIndemnite().getIndice()
+"]";
}
// getters et setters
...
}
On ignorera les annotations @ destinées à la couche [Jpa]. Les différents champs de la classe reflètent les différentes colonnes de la table [EMPLOYES]. Le champ indemnites (ligne 29) reflète le fait que la table [EMPLOYES] a une clé étrangère sur la table [INDEMNITES]. Lorsqu'on manipule un employé, on manipule aussi ses indemnités.
L'entité [Indemnite] est l'expression objet d'une ligne de la table [INDEMNITES] :
L'entité [Indemnite] est la suivante :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
package jpa;
...
@Entity
@Table(name="INDEMNITES")
public class Indemnite implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Version
@Column(name="VERSION",nullable=false)
private int version;
@Column(name="INDICE", nullable=false,unique=true)
private int indice;
@Column(name="BASE_HEURE",nullable=false)
private double baseHeure;
@Column(name="ENTRETIEN_JOUR",nullable=false)
private double entretienJour;
@Column(name="REPAS_JOUR",nullable=false)
private double repasJour;
@Column(name="INDEMNITES_CP",nullable=false)
private double indemnitesCP;
public Indemnite() {
}
public Indemnite(int indice, double baseHeure, double entretienJour, double repasJour, double indemnitesCP){
setIndice(indice);
setBaseHeure(baseHeure);
setEntretienJour(entretienJour);
setRepasJour(repasJour);
setIndemnitesCP(indemnitesCP);
}
@Override
public String toString() {
return "jpa.Indemnite[id=" + getId()
+ ",version="+getVersion()
+",indice="+getIndice()
+",base heure="+getBaseHeure()
+",entretien jour"+getEntretienJour()
+",repas jour="+getRepasJour()
+",indemnités CP="+getIndemnitesCP()
+ "]";
}
// getters et setters
....
}
Les différents champs de la classe reflètent les différentes colonnes de la table [INDEMNITES].
L'entité [Cotisation] est l'expression objet d'une ligne de la table [COTISATIONS] :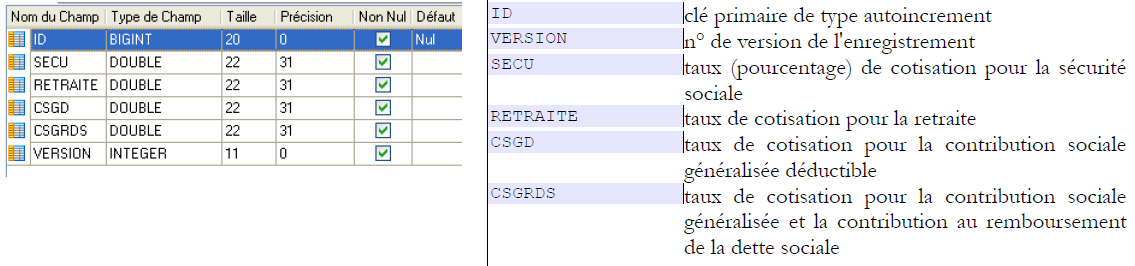
L'entité [Cotisation] est la suivante :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
package jpa;
...
@Entity
@Table(name="COTISATIONS")
public class Cotisation implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Version
@Column(name="VERSION",nullable=false)
private int version;
@Column(name="CSGRDS",nullable=false)
private double csgrds;
@Column(name="CSGD",nullable=false)
private double csgd;
@Column(name="SECU",nullable=false)
private double secu;
@Column(name="RETRAITE",nullable=false)
private double retraite;
public Cotisation() {
}
public Cotisation(double csgrds, double csgd, double secu, double retraite){
setCsgrds(csgrds);
setCsgd(csgd);
setSecu(secu);
setRetraite(retraite);
}
@Override
public String toString() {
return "jpa.Cotisation[id=" + getId() + ",version=" + getVersion()+",csgrds="+getCsgrds()+"" +
",csgd="+getCsgd()+",secu="+getSecu()+",retraite="+getRetraite()+"]";
}
// getters et setters
...
}
Les différents champs de la classe reflètent les différentes colonnes de la table [INDEMNITES].
XVIII-D. Mode de calcul du salaire d'une assistante maternelle▲
L'application web que nous allons écrire va nous permettre de calculer le salaire d'une employée à partir de trois informations :
- l'indice de l'employée
- le nombre de jours travaillés
- le nombre d'heures travaillées
Voici une copie d'écran de calcul d'un salaire :
Nous présentons maintenant le mode de calcul du salaire mensuel d'une assistante maternelle. Il ne prétend pas être celui utilisé dans la réalité. Nous prenons pour exemple, le salaire de Mme Marie Jouveinal qui a travaillé 150 h sur 20 jours pendant le mois à payer.
| Les éléments suivants sont pris en compte : | [TOTALHEURES]: total des heures travaillées dans le mois [TOTALJOURS]: total des jours travaillés dans le mois |
[TOTALHEURES]=150 [TOTALJOURS]= 20 |
| Le salaire de base de l'assistante maternelle est donné par la formule suivante : | [SALAIREBASE]=([TOTALHEURES]*[BASEHEURE])*(1+[INDEMNITESCP]/100) | [SALAIREBASE]=(150*[2.1])*(1+0.15)= 362,25 |
| Un certain nombre de cotisations sociales doivent être prélevées sur ce salaire de base : | Contribution sociale généralisée et contribution au remboursement de la dette sociale : [SALAIREBASE]*[CSGRDS/100] Contribution sociale généralisée déductible : [SALAIREBASE]*[CSGD/100] Sécurité sociale, veuvage, vieillesse : [SALAIREBASE]*[SECU/100] Retraite Complémentaire + AGPF + Assurance Chômage : [SALAIREBASE]*[RETRAITE/100] |
CSGRDS : 12,64 CSGD : 22,28 Sécurité sociale : 34,02 Retraite : 28,55 |
| Total des cotisations sociales : | [COTISATIONSSOCIALES]=[SALAIREBASE]*(CSGRDS+CSGD+SECU+RETRAITE)/100 | [COTISATIONSSOCIALES]=97,48 |
| Par ailleurs, l'assistante maternelle a droit, chaque jour travaillé, à une indemnité d'entretien ainsi qu'à une indemnité de repas. A ce titre elle reçoit les indemnités suivantes : | [Indemnités]=[TOTALJOURS]*(ENTRETIENJOUR+REPASJOUR) | [INDEMNITES]=104 |
| Au final, le salaire net à payer à l'assistante maternelle est le suivant : | [SALAIREBASE]-[COTISATIONSSOCIALES]+[INDEMNITÉS] | [salaire NET]=368,77 |
XVIII-E. L'interface de la couche [métier]▲
Revenons sur l'architecture de l'application que nous construisons :
La couche [web / struts 2] communique avec l'interface de la couche [métier]. Celle-ci est la suivante :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
package metier;
import java.util.List;
import jpa.Employe;
public interface IMetier {
// obtenir la feuille de salaire
FeuilleSalaire calculerFeuilleSalaire(String SS, double nbHeuresTravaillées, int nbJoursTravaillés );
// liste des employés
List<Employe> findAllEmployes();
}
- ligne 8 : la méthode qui nous permettra de calculer le salaire d'un employé
- ligne 10 : la méthode qui nous permettra de remplir le combo des employés
La méthode calculerFeuillesalaire rend une instance de la classe [FeuilleSalaire] suivante :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
package metier;
import java.io.Serializable;
import jpa.Cotisation;
import jpa.Employe;
public class FeuilleSalaire implements Serializable {
// champs privés
private Employe employe;
private Cotisation cotisation;
private ElementsSalaire elementsSalaire;
// constructeurs
public FeuilleSalaire() {
}
public FeuilleSalaire(Employe employe, Cotisation cotisation,
ElementsSalaire elementsSalaire) {
setEmploye(employe);
setCotisation(cotisation);
setElementsSalaire(elementsSalaire);
}
// toString
@Override
public String toString() {
return "[" + employe + "," + cotisation + ","
+ elementsSalaire + "]";
}
// getters et setters
...
}
La feuille de salaire encapsule les informations suivantes :
- ligne 10 : des informations sur l'employé dont on calcule le salaire
- ligne 11 : les différents taux de cotisations
- ligne 12 : des éléments du salaire
La classe [ElementsSalaire] est la suivante :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
package metier;
import java.io.Serializable;
public class ElementsSalaire implements Serializable{
// champs privés
private double salaireBase;
private double cotisationsSociales;
private double indemnitesEntretien;
private double indemnitesRepas;
private double salaireNet;
// constructeurs
public ElementsSalaire() {
}
public ElementsSalaire(double salaireBase, double cotisationsSociales,
double indemnitesEntretien, double indemnitesRepas,
double salaireNet) {
setSalaireBase(salaireBase);
setCotisationsSociales(cotisationsSociales);
setIndemnitesEntretien(indemnitesEntretien);
setIndemnitesRepas(indemnitesRepas);
setSalaireNet(salaireNet);
}
// toString
@Override
public String toString() {
return "[salaire base=" + salaireBase + ",cotisations sociales=" + cotisationsSociales + ",indemnités d'entretien="
+ indemnitesEntretien + ",indemnités de repas=" + indemnitesRepas + ",salaire net="
+ salaireNet + "]";
}
// getters et setters
...
}
- lignes 8-12 : les éléments du salaire
XVIII-F. Le fichier de configuration de Spring▲
L'intégration des couches [métier, dao, jpa] est assurée par le fichier de configuration Spring suivant :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.0.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-2.0.xsd">
<!-- couches applicatives -->
<!-- métier -->
<bean id="metier" class="metier.Metier">
<property name="employeDao" ref="employeDao"/>
<property name="cotisationDao" ref="cotisationDao"/>
</bean>
<!-- dao -->
<bean id="employeDao" class="dao.EmployeDao" />
<bean id="indemniteDao" class="dao.IndemniteDao" />
<bean id="cotisationDao" class="dao.CotisationDao" />
<!-- configuration JPA -->
<bean id="entityManagerFactory" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean">
<property name="dataSource" ref="dataSource" />
<property name="jpaVendorAdapter">
<bean class="org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter">
<property name="databasePlatform" value="org.hibernate.dialect.MySQL5InnoDBDialect" />
</bean>
</property>
<property name="loadTimeWeaver">
<bean class="org.springframework.instrument.classloading.InstrumentationLoadTimeWeaver" />
</property>
</bean>
<!-- la source de données DBCP -->
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver" />
<property name="url" value="jdbc:mysql://localhost:3306/dbpam_hibernate" />
<property name="username" value="root" />
<property name="password" value="" />
</bean>
<!-- le gestionnaire de transactions -->
<tx:annotation-driven transaction-manager="txManager" />
<bean id="txManager" class="org.springframework.orm.jpa.JpaTransactionManager">
<property name="entityManagerFactory" ref="entityManagerFactory" />
</bean>
<!-- traduction des exceptions -->
<bean class="org.springframework.dao.annotation.PersistenceExceptionTranslationPostProcessor" />
<!-- persistence -->
<bean class="org.springframework.orm.jpa.support.PersistenceAnnotationBeanPostProcessor" />
</beans>
Nous n'essaierons pas d'expliquer cette configuration. Elle est nécessaire pour l'instanciation et l'intégration des couches [métier, dao, jpa]. Notre application web qui va s'appuyer sur ces couches devra donc reprendre cette configuration. On notera que les lignes 32-37 configurent les caractéristiques Jdbc de la base de données. Le lecteur qui voudrait changer de base de données doit modifier ces lignes.
Pour plus d'informations sur cette configuration, on lira le document Introduction à Java EE 5 disponible à l'Url [http://tahe.developpez.com/java/javaee].
